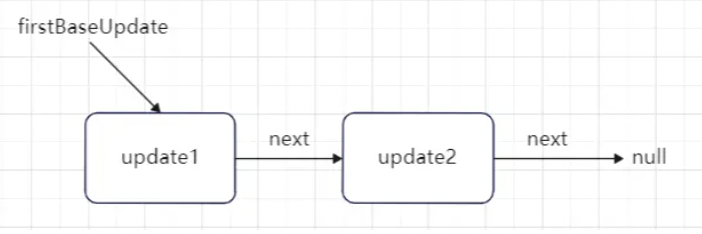
import * as BeforeInputEventPlugin from'./plugins/BeforeInputEventPlugin'; import * as ChangeEventPlugin from'./plugins/ChangeEventPlugin'; import * as EnterLeaveEventPlugin from'./plugins/EnterLeaveEventPlugin'; import * as SelectEventPlugin from'./plugins/SelectEventPlugin'; import * as SimpleEventPlugin from'./plugins/SimpleEventPlugin';
// \react-dom-bindings\src\events\DOMPluginEventSystem.js // 事件绑定 exportfunctionlistenToAllSupportedEvents(rootContainerElement: EventTarget) { if (!(rootContainerElement: any)[listeningMarker]) { // sy 防止重复绑定 (rootContainerElement: any)[listeningMarker] = true; allNativeEvents.forEach(domEventName => { // We handle selectionchange separately because it // doesn't bubble and needs to be on the document. // 单独处理selectionchange事件,因为它不会冒泡,需要在文档上处理。 if (domEventName !== 'selectionchange') { if (!nonDelegatedEvents.has(domEventName)) { // ! 这些事件都是委托在rootContainerElement上的 // nonDelegatedEvents中都是不需要委托的事件,也就是不需要冒泡的,如cancel、close、invalid、load、scroll、scrollend、toggle等 listenToNativeEvent(domEventName, false, rootContainerElement); } listenToNativeEvent(domEventName, true, rootContainerElement); } });
// 单独处理selectionchange事件 const ownerDocument = (rootContainerElement: any).nodeType === DOCUMENT_NODE ? rootContainerElement : (rootContainerElement: any).ownerDocument; if (ownerDocument !== null) { // The selectionchange event also needs deduplication // but it is attached to the document. // selectionchange事件也需要去重,但它附加在document上。 if (!(ownerDocument: any)[listeningMarker]) { (ownerDocument: any)[listeningMarker] = true; listenToNativeEvent('selectionchange', false, ownerDocument); } } } }
// \react-dom-bindings\src\events\DOMPluginEventSystem.js // We should not delegate these events to the container, but rather // set them on the actual target element itself. This is primarily // because these events do not consistently bubble in the DOM. // 我们不应该将这些事件委托给容器,而是应该直接在实际的目标元素上设置它们。这主要是因为这些事件在DOM中的冒泡行为并不一致。 exportconst nonDelegatedEvents: Set<DOMEventName> = newSet([ 'cancel', 'close', 'invalid', 'load', 'scroll', 'scrollend', 'toggle', // In order to reduce bytes, we insert the above array of media events // into this Set. Note: the "error" event isn't an exclusive media event, // and can occur on other elements too. Rather than duplicate that event, // we just take it from the media events array. // 为了减少字节数,我们将上述媒体事件数组插入到这个 Set 中。 // 注意:"error" 事件并不是一个独占的媒体事件,也可能发生在其他元素上。我们不会重复这个事件,而是直接从媒体事件数组中取出。 ...mediaEventTypes, ]); // List of events that need to be individually attached to media elements. // 需要分别附加到媒体元素的事件列表。 exportconst mediaEventTypes: Array<DOMEventName> = [ 'abort', 'canplay', 'canplaythrough', 'durationchange', 'emptied', 'encrypted', 'ended', 'error', 'loadeddata', 'loadedmetadata', 'loadstart', 'pause', 'play', 'playing', 'progress', 'ratechange', 'resize', 'seeked', 'seeking', 'stalled', 'suspend', 'timeupdate', 'volumechange', 'waiting', ];
// \packages\react-dom-bindings\src\events\DOMPluginEventSystem.js functionaddTrappedEventListener( targetContainer: EventTarget, // 事件挂载节点,也就是 div#root domEventName: DOMEventName, // 原生事件名,比如 click eventSystemFlags: EventSystemFlags, //4 表示捕获,0 表示冒泡 isCapturePhaseListener: boolean, // true 表示捕获阶段,false 表示冒泡阶段 isDeferredListenerForLegacyFBSupport?: boolean, ) { // 获取对应事件,事件定义在ReactDOMEventListener.js中 // 如DiscreteEventPriority对应dispatchDiscreteEvent,ContinuousEventPriority对应dispatchContinuousEvent // 创建一个事件监听器 let listener = createEventListenerWrapperWithPriority( targetContainer, domEventName, eventSystemFlags, ); // If passive option is not supported, then the event will be // active and not passive. let isPassiveListener: void | boolean = undefined; if (passiveBrowserEventsSupported) { // sy // Browsers introduced an intervention, making these events // passive by default on document. React doesn't bind them // to document anymore, but changing this now would undo // the performance wins from the change. So we emulate // the existing behavior manually on the roots now. // 浏览器引入了一种干预措施,使这些事件在document上默认为passive状态。 // React不再将它们绑定到document上,但是现在改变这一点将会撤销之前的性能优势。 // 因此,我们现在在根节点上手动模拟现有的行为。 // https://github.com/facebook/react/issues/19651 if ( domEventName === 'touchstart' || domEventName === 'touchmove' || domEventName === 'wheel' ) { isPassiveListener = true; } }
let unsubscribeListener; // When legacyFBSupport is enabled, it's for when we // want to add a one time event listener to a container. // This should only be used with enableLegacyFBSupport // due to requirement to provide compatibility with // internal FB www event tooling. This works by removing // the event listener as soon as it is invoked. We could // also attempt to use the {once: true} param on // addEventListener, but that requires support and some // browsers do not support this today, and given this is // to support legacy code patterns, it's likely they'll // need support for such browsers. // 当启用legacyFBSupport时,是为了当我们想要向container添加一次性事件监听器时使用。 // 这应该只与enableLegacyFBSupport一起使用,因为需要与内部FB www事件工具提供的兼容性。 // 这通过在调用后立即移除事件监听器来实现。我们也可以尝试在addEventListener上使用{once: true}参数,但这需要支持, // 一些浏览器今天不支持这一点,考虑到这是为了支持传统代码模式,它们可能需要支持这些浏览器。 if (enableLegacyFBSupport && isDeferredListenerForLegacyFBSupport) { const originalListener = listener; listener = function (...p) { removeEventListener( targetContainer, domEventName, unsubscribeListener, isCapturePhaseListener, ); return originalListener.apply(this, p); }; } // TODO: There are too many combinations here. Consolidate them.
exportfunctiongetEventPriority(domEventName: DOMEventName): EventPriority{ switch (domEventName) { // Used by SimpleEventPlugin: case'cancel': case'click': case'close': case'contextmenu': case'copy': case'cut': case'auxclick': case'dblclick': case'dragend': case'dragstart': case'drop': case'focusin': case'focusout': case'input': case'invalid': case'keydown': case'keypress': case'keyup': case'mousedown': case'mouseup': case'paste': case'pause': case'play': case'pointercancel': case'pointerdown': case'pointerup': case'ratechange': case'reset': case'resize': case'seeked': case'submit': case'touchcancel': case'touchend': case'touchstart': case'volumechange': // Used by polyfills: (fall through) case'change': case'selectionchange': case'textInput': case'compositionstart': case'compositionend': case'compositionupdate': // Only enableCreateEventHandleAPI: (fall through) case'beforeblur': case'afterblur': // Not used by React but could be by user code: (fall through) case'beforeinput': case'blur': case'fullscreenchange': case'focus': case'hashchange': case'popstate': case'select': case'selectstart': return DiscreteEventPriority; case'drag': case'dragenter': case'dragexit': case'dragleave': case'dragover': case'mousemove': case'mouseout': case'mouseover': case'pointermove': case'pointerout': case'pointerover': case'scroll': case'toggle': case'touchmove': case'wheel': // Not used by React but could be by user code: (fall through) case'mouseenter': case'mouseleave': case'pointerenter': case'pointerleave': return ContinuousEventPriority; case'message': { // We might be in the Scheduler callback. // Eventually this mechanism will be replaced by a check // of the current priority on the native scheduler. const schedulerPriority = getCurrentSchedulerPriorityLevel(); switch (schedulerPriority) { case ImmediateSchedulerPriority: return DiscreteEventPriority; case UserBlockingSchedulerPriority: return ContinuousEventPriority; case NormalSchedulerPriority: case LowSchedulerPriority: // TODO: Handle LowSchedulerPriority, somehow. Maybe the same lane as hydration. return DefaultEventPriority; case IdleSchedulerPriority: return IdleEventPriority; default: return DefaultEventPriority; } } default: return DefaultEventPriority; } }
if ( queueIfContinuousEvent( blockedOn, domEventName, eventSystemFlags, targetContainer, nativeEvent, ) ) { nativeEvent.stopPropagation(); return; } // We need to clear only if we didn't queue because // queueing is accumulative. clearIfContinuousEvent(domEventName, nativeEvent);
// This is not replayable so we'll invoke it but without a target, // in case the event system needs to trace it. dispatchEventForPluginEventSystem( domEventName, eventSystemFlags, nativeEvent, null, targetContainer, ); }
// Returns a SuspenseInstance or Container if it's blocked. // The return_targetInst field above is conceptually part of the return value. // 如果被阻塞,返回一个 SuspenseInstance 或 Container。 // 上面的 return_targetInst 字段在概念上是返回值的一部分。 exportfunctionfindInstanceBlockingTarget( targetNode: Node, ): null | Container | SuspenseInstance{ // TODO: Warn if _enabled is false.
return_targetInst = null;
// 通过 targetNode 获取最近的 Fiber 实例 let targetInst = getClosestInstanceFromNode(targetNode);
if (targetInst !== null) { // 寻找最近的已挂载的 Fiber 实例 const nearestMounted = getNearestMountedFiber(targetInst); if (nearestMounted === null) { // This tree has been unmounted already. Dispatch without a target. // 这棵树已经被卸载了。在没有目标的情况下进行派发。 targetInst = null; } else { const tag = nearestMounted.tag; if (tag === SuspenseComponent) { // 寻找最近的已挂载的 Suspense 实例 const instance = getSuspenseInstanceFromFiber(nearestMounted); if (instance !== null) { // Queue the event to be replayed later. Abort dispatching since we // don't want this event dispatched twice through the event system. // TODO: If this is the first discrete event in the queue. Schedule an increased // priority for this boundary. // 将事件排队以便稍后重播。中止事件分发,因为我们不希望通过事件系统将此事件分发两次。 return instance; } // This shouldn't happen, something went wrong but to avoid blocking // the whole system, dispatch the event without a target. // TODO: Warn. // 这不应该发生,出了点问题,但为了避免阻塞整个系统,以没有目标的方式分发事件。 targetInst = null; } elseif (tag === HostRoot) { const root: FiberRoot = nearestMounted.stateNode; if (isRootDehydrated(root)) { // If this happens during a replay something went wrong and it might block // the whole system. return getContainerFromFiber(nearestMounted); } targetInst = null; } elseif (nearestMounted !== targetInst) { // If we get an event (ex: img onload) before committing that // component's mount, ignore it for now (that is, treat it as if it was an // event on a non-React tree). We might also consider queueing events and // dispatching them after the mount. // 如果在提交该组件的挂载之前收到事件(例如:图片加载完成),暂时忽略它(也就是,将其视为在非React树上的事件)。 // 我们也可以考虑将事件排队,并在挂载后分发它们。 targetInst = null; } } } return_targetInst = targetInst; // We're not blocked on anything. // 没有阻塞 returnnull; }
// If we are using the legacy FB support flag, we // defer the event to the null with a one // time event listener so we can defer the event. if ( enableLegacyFBSupport && // If our event flags match the required flags for entering // FB legacy mode and we are processing the "click" event, // then we can defer the event to the "document", to allow // for legacy FB support, where the expected behavior was to // match React < 16 behavior of delegated clicks to the doc. domEventName === 'click' && (eventSystemFlags & SHOULD_NOT_DEFER_CLICK_FOR_FB_SUPPORT_MODE) === 0 && !isReplayingEvent(nativeEvent) ) { deferClickToDocumentForLegacyFBSupport(domEventName, targetContainer); return; } if (targetInst !== null) { // The below logic attempts to work out if we need to change // the target fiber to a different ancestor. We had similar logic // in the legacy event system, except the big difference between // systems is that the modern event system now has an event listener // attached to each React Root and React Portal Root. Together, // the DOM nodes representing these roots are the "rootContainer". // To figure out which ancestor instance we should use, we traverse // up the fiber tree from the target instance and attempt to find // root boundaries that match that of our current "rootContainer". // If we find that "rootContainer", we find the parent fiber // sub-tree for that root and make that our ancestor instance. let node: null | Fiber = targetInst;
mainLoop: while (true) { if (node === null) { // 事件没有对应的fiber,没法执行事件,退出 return; } const nodeTag = node.tag; if (nodeTag === HostRoot || nodeTag === HostPortal) { let container = node.stateNode.containerInfo; if (isMatchingRootContainer(container, targetContainerNode)) { // container和targetContainerNode相等,说明找到了对应的rootContainer break; } if (nodeTag === HostPortal) { // The target is a portal, but it's not the rootContainer we're looking for. // Normally portals handle their own events all the way down to the root. // So we should be able to stop now. However, we don't know if this portal // was part of *our* root. let grandNode = node.return; while (grandNode !== null) { const grandTag = grandNode.tag; if (grandTag === HostRoot || grandTag === HostPortal) { const grandContainer = grandNode.stateNode.containerInfo; if ( isMatchingRootContainer(grandContainer, targetContainerNode) ) { // This is the rootContainer we're looking for and we found it as // a parent of the Portal. That means we can ignore it because the // Portal will bubble through to us. return; } } grandNode = grandNode.return; } } // Now we need to find it's corresponding host fiber in the other // tree. To do this we can use getClosestInstanceFromNode, but we // need to validate that the fiber is a host instance, otherwise // we need to traverse up through the DOM till we find the correct // node that is from the other tree. while (container !== null) { const parentNode = getClosestInstanceFromNode(container); if (parentNode === null) { return; } const parentTag = parentNode.tag; if ( parentTag === HostComponent || parentTag === HostText || (enableFloat ? parentTag === HostHoistable : false) || parentTag === HostSingleton ) { node = ancestorInst = parentNode; continue mainLoop; } container = container.parentNode; } } node = node.return; } } }
// \react-dom-bindings\src\events\ReactDOMUpdateBatching.js exportfunctionbatchedUpdates(fn, a, b) { if (isInsideEventHandler) { // If we are currently inside another batch, we need to wait until it // fully completes before restoring state. // 如果我们当前正在另一个批处理中,需要等待其完全完成后再恢复状态。 return fn(a, b); } isInsideEventHandler = true; try { return batchedUpdatesImpl(fn, a, b); } finally { isInsideEventHandler = false; finishEventHandler(); } }
// \packages\react-reconciler\src\ReactFiberWorkLoop.js exportfunctionbatchedUpdates<A, R>(fn: A => R, a: A): R{ const prevExecutionContext = executionContext; executionContext |= BatchedContext; try { return fn(a); } finally { executionContext = prevExecutionContext; // If there were legacy sync updates, flush them at the end of the outer // most batchedUpdates-like method. if ( executionContext === NoContext && // Treat `act` as if it's inside `batchedUpdates`, even in legacy mode. !(__DEV__ && ReactCurrentActQueue.isBatchingLegacy) ) { resetRenderTimer(); flushSyncWorkOnLegacyRootsOnly(); } } }
const accumulateTargetOnly = !inCapturePhase && // TODO: ideally, we'd eventually add all events from // nonDelegatedEvents list in DOMPluginEventSystem. // Then we can remove this special list. // This is a breaking change that can wait until React 18. // TODO:理想情况下,我们最终会将nonDelegatedEvents列表中的所有事件添加到DOMPluginEventSystem中。 // 然后我们可以移除这个特殊列表。这是一个破坏性的变更,可以等到React 18再处理。 (domEventName === 'scroll' || domEventName === 'scrollend');
exportfunctionprocessDispatchQueue( dispatchQueue: DispatchQueue, eventSystemFlags: EventSystemFlags, ): void{ const inCapturePhase = (eventSystemFlags & IS_CAPTURE_PHASE) !== 0; for (let i = 0; i < dispatchQueue.length; i++) { const {event, listeners} = dispatchQueue[i]; processDispatchQueueItemsInOrder(event, listeners, inCapturePhase); // event system doesn't use pooling. } // This would be a good time to rethrow if any of the event handlers threw. rethrowCaughtError(); }
let oldFiber = currentFirstChild; let lastPlacedIndex = 0; let newIdx = 0; let nextOldFiber = null; // ! 1. 从左边往右遍历,比较新老节点,如果节点可以复用,继续往右,否则就停止 for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) { if (oldFiber.index > newIdx) { nextOldFiber = oldFiber; oldFiber = null; } else { nextOldFiber = oldFiber.sibling; } const newFiber = updateSlot( returnFiber, oldFiber, newChildren[newIdx], lanes, debugInfo, ); if (newFiber === null) { // TODO: This breaks on empty slots like null children. That's // unfortunate because it triggers the slow path all the time. We need // a better way to communicate whether this was a miss or null, // boolean, undefined, etc. if (oldFiber === null) { oldFiber = nextOldFiber; } break; } if (shouldTrackSideEffects) { if (oldFiber && newFiber.alternate === null) { // We matched the slot, but we didn't reuse the existing fiber, so we // need to delete the existing child. deleteChild(returnFiber, oldFiber); } } lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx); if (previousNewFiber === null) { // TODO: Move out of the loop. This only happens for the first run. resultingFirstChild = newFiber; } else { // TODO: Defer siblings if we're not at the right index for this slot. // I.e. if we had null values before, then we want to defer this // for each null value. However, we also don't want to call updateSlot // with the previous one. previousNewFiber.sibling = newFiber; } previousNewFiber = newFiber; oldFiber = nextOldFiber; }
// !2.1 新节点没了,(老节点还有)。则删除剩余的老节点即可 // 0 1 2 3 4 // 0 1 2 3 if (newIdx === newChildren.length) { // We've reached the end of the new children. We can delete the rest. deleteRemainingChildren(returnFiber, oldFiber); if (getIsHydrating()) { const numberOfForks = newIdx; pushTreeFork(returnFiber, numberOfForks); } return resultingFirstChild; } // ! 2.2 (新节点还有),老节点没了 // 0 1 2 3 4 // 0 1 2 3 4 5 if (oldFiber === null) { // If we don't have any more existing children we can choose a fast path // since the rest will all be insertions. for (; newIdx < newChildren.length; newIdx++) { const newFiber = createChild( returnFiber, newChildren[newIdx], lanes, debugInfo, ); if (newFiber === null) { continue; } lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx); if (previousNewFiber === null) { // TODO: Move out of the loop. This only happens for the first run. resultingFirstChild = newFiber; } else { previousNewFiber.sibling = newFiber; } previousNewFiber = newFiber; } if (getIsHydrating()) { const numberOfForks = newIdx; pushTreeFork(returnFiber, numberOfForks); } return resultingFirstChild; }
// !2.3 新老节点都还有节点,但是因为老fiber是链表,不方便快速get与delete, // ! 因此把老fiber链表中的节点放入Map中,后续操作这个Map的get与delete // 0 1| 4 5 // 0 1| 7 8 2 3 // Add all children to a key map for quick lookups. const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// Keep scanning and use the map to restore deleted items as moves. for (; newIdx < newChildren.length; newIdx++) { const newFiber = updateFromMap( existingChildren, returnFiber, newIdx, newChildren[newIdx], lanes, debugInfo, ); if (newFiber !== null) { if (shouldTrackSideEffects) { if (newFiber.alternate !== null) { // The new fiber is a work in progress, but if there exists a // current, that means that we reused the fiber. We need to delete // it from the child list so that we don't add it to the deletion // list. existingChildren.delete( newFiber.key === null ? newIdx : newFiber.key, ); } } lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx); if (previousNewFiber === null) { resultingFirstChild = newFiber; } else { previousNewFiber.sibling = newFiber; } previousNewFiber = newFiber; } }
// !3. 如果是组件更新阶段,此时新节点已经遍历完了,能复用的老节点都用完了, // ! 则最后查找Map里是否还有元素,如果有,则证明是新节点里不能复用的,也就是要被删除的元素,此时删除这些元素就可以了 if (shouldTrackSideEffects) { // Any existing children that weren't consumed above were deleted. We need // to add them to the deletion list. existingChildren.forEach(child => deleteChild(returnFiber, child)); }
switch (parentFiber.tag) { case HostSingleton: { if (supportsSingletons) { const parent: Instance = parentFiber.stateNode; const before = getHostSibling(finishedWork); // We only have the top Fiber that was inserted but we need to recurse down its // children to find all the terminal nodes. insertOrAppendPlacementNode(finishedWork, before, parent); break; } // Fall through } case HostComponent: { const parent: Instance = parentFiber.stateNode; if (parentFiber.flags & ContentReset) {
console.log('%c [ ]-1832', 'font-size:13px; background:pink; color:#bf2c9f;', ) // Reset the text content of the parent before doing any insertions resetTextContent(parent); // Clear ContentReset from the effect tag parentFiber.flags &= ~ContentReset; }
const before = getHostSibling(finishedWork); // We only have the top Fiber that was inserted but we need to recurse down its // children to find all the terminal nodes. insertOrAppendPlacementNode(finishedWork, before, parent); break; } case HostRoot: case HostPortal: { const parent: Container = parentFiber.stateNode.containerInfo; const before = getHostSibling(finishedWork); insertOrAppendPlacementNodeIntoContainer(finishedWork, before, parent); break; } default: thrownewError( 'Invalid host parent fiber. This error is likely caused by a bug ' + 'in React. Please file an issue.', ); } }
functiongetHostSibling(fiber: Fiber): ?Instance{ // We're going to search forward into the tree until we find a sibling host // node. Unfortunately, if multiple insertions are done in a row we have to // search past them. This leads to exponential search for the next sibling. // TODO: Find a more efficient way to do this. let node: Fiber = fiber; siblings: while (true) { // If we didn't find anything, let's try the next sibling. while (node.sibling === null) { if (node.return === null || isHostParent(node.return)) { // If we pop out of the root or hit the parent the fiber we are the // last sibling. returnnull; } node = node.return; } node.sibling.return = node.return; node = node.sibling; // 找到下一个兄弟节点 while ( node.tag !== HostComponent && node.tag !== HostText && (!supportsSingletons ? true : node.tag !== HostSingleton) && node.tag !== DehydratedFragment ) { // If it is not host node and, we might have a host node inside it. // Try to search down until we find one. if (node.flags & Placement) { // If we don't have a child, try the siblings instead. continue siblings; } // If we don't have a child, try the siblings instead. // We also skip portals because they are not part of this host tree. if (node.child === null || node.tag === HostPortal) { continue siblings; } else { node.child.return = node; node = node.child; } } // Check if this host node is stable or about to be placed. // 判断节点是稳定的,即不需要移动或是新增的 if (!(node.flags & Placement)) { // Found it! // 就找到了这个节点了 return node.stateNode; } } }
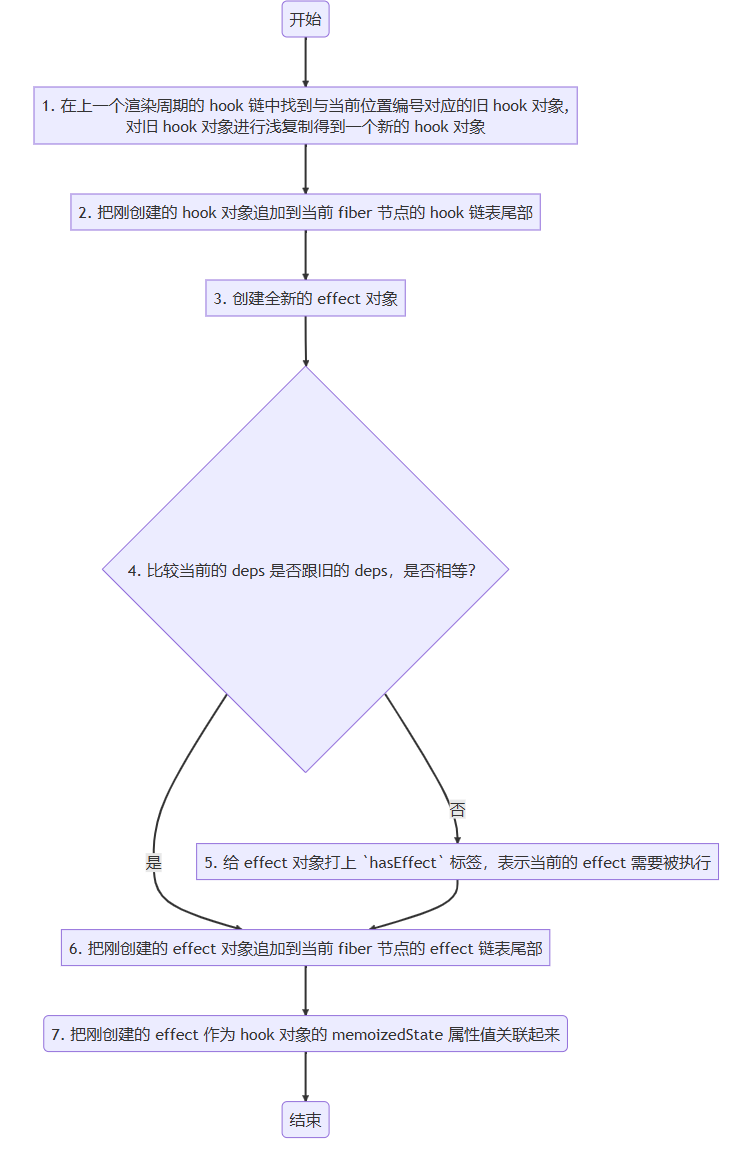
// currentHook is null on initial mount when rerendering after a render phase // state update or for strict mode. if (currentHook !== null) { if (nextDeps !== null) { const prevEffect: Effect = currentHook.memoizedState; const prevDeps = prevEffect.deps; // 比较两次依赖数组中的值是否有变化 if (areHookInputsEqual(nextDeps, prevDeps)) { hook.memoizedState = pushEffect(hookFlags, create, inst, nextDeps); return; } } }
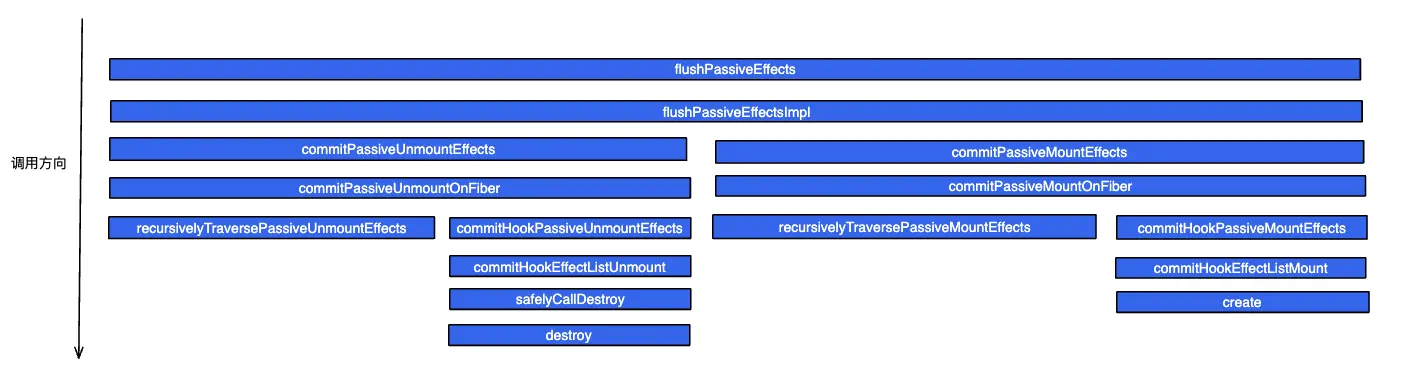
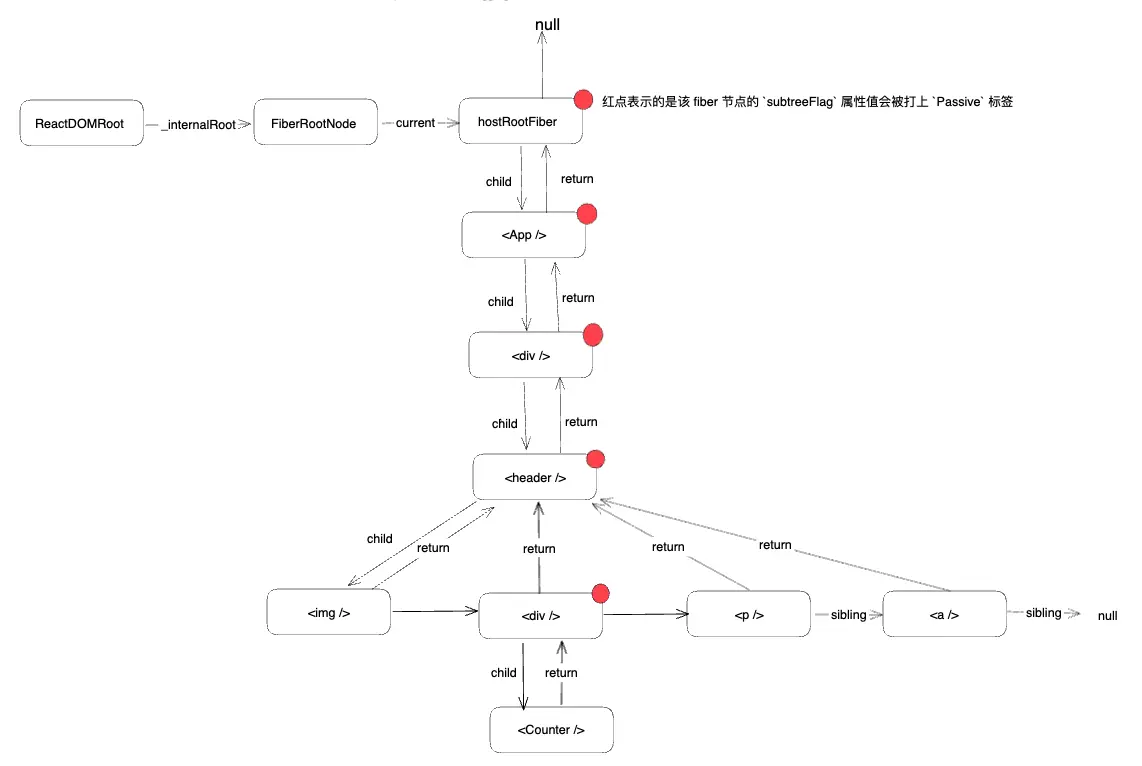
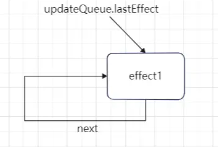
if ( (finishedWork.subtreeFlags & PassiveMask) !== NoFlags || (finishedWork.flags & PassiveMask) !== NoFlags ) { if (!rootDoesHavePassiveEffects) { rootDoesHavePassiveEffects = true; pendingPassiveEffectsRemainingLanes = remainingLanes; // workInProgressTransitions might be overwritten, so we want // to store it in pendingPassiveTransitions until they get processed // We need to pass this through as an argument to commitRoot // because workInProgressTransitions might have changed between // the previous render and commit if we throttle the commit // with setTimeout pendingPassiveTransitions = transitions; scheduleCallback(NormalSchedulerPriority, () => { // ! 1. 异步执行 passive effects flushPassiveEffects(); // This render triggered passive effects: release the root cache pool // *after* passive effects fire to avoid freeing a cache pool that may // be referenced by a node in the tree (HostRoot, Cache boundary etc) returnnull; }); } }
// Update the return pointer so the tree is consistent. This is a code // smell because it assumes the commit phase is never concurrent with // the render phase. Will address during refactor to alternate model. child.return = completedWork;
child = child.sibling; } } // ! 子树的flags completedWork.subtreeFlags |= subtreeFlags; } else { // Bubble up the earliest expiration time. if (enableProfilerTimer && (completedWork.mode & ProfileMode) !== NoMode) { // In profiling mode, resetChildExpirationTime is also used to reset // profiler durations. let treeBaseDuration = ((completedWork.selfBaseDuration: any): number);
let child = completedWork.child; while (child !== null) { newChildLanes = mergeLanes( newChildLanes, mergeLanes(child.lanes, child.childLanes), );
// "Static" flags share the lifetime of the fiber/hook they belong to, // so we should bubble those up even during a bailout. All the other // flags have a lifetime only of a single render + commit, so we should // ignore them. subtreeFlags |= child.subtreeFlags & StaticMask; subtreeFlags |= child.flags & StaticMask;
// $FlowFixMe[unsafe-addition] addition with possible null/undefined value treeBaseDuration += child.treeBaseDuration; child = child.sibling; }
// "Static" flags share the lifetime of the fiber/hook they belong to, // so we should bubble those up even during a bailout. All the other // flags have a lifetime only of a single render + commit, so we should // ignore them. // “静态”标志(Static flags)与它们所属的 Fiber 或 Hook 共享生命周期,因此即使在放弃(bailout)时,也应该将这些flags向上冒泡。 // 而其他所有flags仅在单次render + commit 的生命周期内存在,因此我们应该忽略它们。 // ! 2. 将他们的(subtreeFlags&StaticMask)和flags合并到subtreeFlags中 subtreeFlags |= child.subtreeFlags & StaticMask; subtreeFlags |= child.flags & StaticMask;
// Update the return pointer so the tree is consistent. This is a code // smell because it assumes the commit phase is never concurrent with // the render phase. Will address during refactor to alternate model. // 更新return pointer以保持树的一致性。这被描述为一种代码异味(code smell),因为它假设commit阶段永远不会与 render 阶段并发。 // 在重构为交替模型(alternate model)时将会解决这个问题。 child.return = completedWork;
switch (finishedWork.tag) { case FunctionComponent: case ForwardRef: case MemoComponent: case SimpleMemoComponent: { recursivelyTraverseMutationEffects(root, finishedWork); commitReconciliationEffects(finishedWork);
switch (finishedWork.tag) { case FunctionComponent: case ForwardRef: case SimpleMemoComponent: { recursivelyTraverseLayoutEffects( finishedRoot, finishedWork, committedLanes );
if (flags & Update) { commitHookLayoutEffects(finishedWork, Layout | HasEffect); }
functionworkLoopConcurrent() { // Perform work until Scheduler asks us to yield while (workInProgress !== null && !shouldYield()) { // $FlowFixMe[incompatible-call] found when upgrading Flow performUnitOfWork(workInProgress); } }
// Determine the next lanes to work on, and their priority. const workInProgressRoot = getWorkInProgressRoot(); const workInProgressRootRenderLanes = getWorkInProgressRootRenderLanes();
const existingCallbackNode = root.callbackNode; if ( // Check if there's nothing to work on nextLanes === NoLanes || // If this root is currently suspended and waiting for data to resolve, don't // schedule a task to render it. We'll either wait for a ping, or wait to // receive an update. // // Suspended render phase (root === workInProgressRoot && isWorkLoopSuspendedOnData()) || // Suspended commit phase root.cancelPendingCommit !== null ) { // Fast path: There's nothing to work on. if (existingCallbackNode !== null) { cancelCallback(existingCallbackNode); } root.callbackNode = null; root.callbackPriority = NoLane; return NoLane; }
// Schedule a new callback in the host environment. if (includesSyncLane(nextLanes)) { // sy- setState // sy-no 初次渲染 // 同步工作始终在微任务结束时刷新,因此我们不需要安排额外的任务。 if (existingCallbackNode !== null) { cancelCallback(existingCallbackNode); } root.callbackPriority = SyncLane; root.callbackNode = null; return SyncLane; } else {
// We use the highest priority lane to represent the priority of the callback. const existingCallbackPriority = root.callbackPriority; const newCallbackPriority = getHighestPriorityLane(nextLanes); if ( newCallbackPriority === existingCallbackPriority && // Special case related to `act`. If the currently scheduled task is a // Scheduler task, rather than an `act` task, cancel it and re-schedule // on the `act` queue. !( __DEV__ && ReactCurrentActQueue.current !== null && existingCallbackNode !== fakeActCallbackNode ) ) { // The priority hasn't changed. We can reuse the existing task. return newCallbackPriority; } else { // Cancel the existing callback. We'll schedule a new one below. cancelCallback(existingCallbackNode); }
let schedulerPriorityLevel; switch (lanesToEventPriority(nextLanes)) { case DiscreteEventPriority: schedulerPriorityLevel = ImmediateSchedulerPriority; break; case ContinuousEventPriority: schedulerPriorityLevel = UserBlockingSchedulerPriority; break; case DefaultEventPriority: // 32 // ? sy 页面初次渲染、transition(128) schedulerPriorityLevel = NormalSchedulerPriority; // 3 break; case IdleEventPriority: schedulerPriorityLevel = IdleSchedulerPriority; break; default: schedulerPriorityLevel = NormalSchedulerPriority; break; }
// Flush any pending passive effects before deciding which lanes to work on, // in case they schedule additional work. const originalCallbackNode = root.callbackNode; // ...
if (exitStatus !== RootInProgress) { let renderWasConcurrent = shouldTimeSlice; do { if (exitStatus === RootDidNotComplete) { // The render unwound without completing the tree. This happens in special // cases where need to exit the current render without producing a // consistent tree or committing. markRootSuspended(root, lanes, NoLane); } else { // ! 2. render结束,做一些检查
exportfunctiongetContinuationForRoot( root: FiberRoot, originalCallbackNode: mixed, ): RenderTaskFn | null{ // This is called at the end of `performConcurrentWorkOnRoot` to determine // if we need to schedule a continuation task. // // Usually `scheduleTaskForRootDuringMicrotask` only runs inside a microtask; // however, since most of the logic for determining if we need a continuation // versus a new task is the same, we cheat a bit and call it here. This is // only safe to do because we know we're at the end of the browser task. // So although it's not an actual microtask, it might as well be. scheduleTaskForRootDuringMicrotask(root, now()); if (root.callbackNode === originalCallbackNode) { // The task node scheduled for this root is the same one that's // currently executed. Need to return a continuation. return performConcurrentWorkOnRoot.bind(null, root); } returnnull; }
const callback = currentTask.callback; if (typeof callback === 'function') { // ... const continuationCallback = callback(didUserCallbackTimeout); // 返回值continuationCallback是函数,也就是performConcurrentWorkOnRoot执行后的返回值performConcurrentWorkOnRoot.bind(null, root)或null,如果是函数就继续,不是的话,如果判断如果currentTask === peek(taskQueue),currentTask 出队 if (typeof continuationCallback === 'function') { // If a continuation is returned, immediately yield to the main thread // regardless of how much time is left in the current time slice. // $FlowFixMe[incompatible-use] found when upgrading Flow currentTask.callback = continuationCallback; if (enableProfiling) { // $FlowFixMe[incompatible-call] found when upgrading Flow markTaskYield(currentTask, currentTime); } advanceTimers(currentTime); returntrue; } else { if (enableProfiling) { // $FlowFixMe[incompatible-call] found when upgrading Flow markTaskCompleted(currentTask, currentTime); // $FlowFixMe[incompatible-use] found when upgrading Flow currentTask.isQueued = false; } if (currentTask === peek(taskQueue)) { pop(taskQueue); } advanceTimers(currentTime); } } else { pop(taskQueue); } currentTask = peek(taskQueue);
// 在 调度更新的过程中会被调用 // 检查是有lanes挨饿,如果有,则标记他们过期,即提升优先级(以便下次执行)。 exportfunctionmarkStarvedLanesAsExpired( root: FiberRoot, currentTime: number, ): void{ // TODO: This gets called every time we yield. We can optimize by storing // the earliest expiration time on the root. Then use that to quickly bail out // of this function.
// Iterate through the pending lanes and check if we've reached their // expiration time. If so, we'll assume the update is being starved and mark // it as expired to force it to finish. // 遍历pending lanes,并检查是否已经达到它们的过期时间。 // 如果是,我们就认为这个update挨饿了,并将其标记为已过期,以强制其完成。 // TODO: We should be able to replace this with upgradePendingLanesToSync // // We exclude retry lanes because those must always be time sliced, in order // to unwrap uncached promises. // TODO: Write a test for this let lanes = enableRetryLaneExpiration ? pendingLanes // ? sy : pendingLanes & ~RetryLanes;
while (lanes > 0) { // 下面两行代码的作用是找到lanes中最低位的1,即优先级最 const index = pickArbitraryLaneIndex(lanes); // 把1左移index位,即得到一个只有第index位为1的子掩码 const lane = 1 << index;
const expirationTime = expirationTimes[index]; if (expirationTime === NoTimestamp) { // sy- console.log('%c [ ]-1469', 'font-size:13px; background:pink; color:#bf2c9f;', lane) // Found a pending lane with no expiration time. If it's not suspended, or // if it's pinged, assume it's CPU-bound. Compute a new expiration time // using the current time. // 如果这个 pending lane 没有过期时间 // 如果它没有被挂起且需要更新,我们就认为它是CPU密集型操作。 // 用当前时间计算出一个新的过期时间给它。 // CPU bound / IO Bound if ( (lane & suspendedLanes) === NoLanes || (lane & pingedLanes) !== NoLanes ) { // sy- console.log('%c [ 饿死 ]-482', 'font-size:13px; background:pink; color:#bf2c9f;', lane) // Assumes timestamps are monotonically increasing. // 假设timestamps(时间戳)是单调递增的 expirationTimes[index] = computeExpirationTime(lane, currentTime); } } elseif (expirationTime <= currentTime) { // 这个 pending lane 已经过期了 // This lane expired root.expiredLanes |= lane; } // 把lane从lanes中移除,计算下一个lane lanes &= ~lane; } }
// 检查root是否包含过期的lane exportfunctionincludesExpiredLane(root: FiberRoot, lanes: Lanes): boolean{ // This is a separate check from includesBlockingLane because a lane can // expire after a render has already started. return (lanes & root.expiredLanes) !== NoLanes; }
exportfunctionrequestUpdateLane(fiber: Fiber): Lane{ // Special cases const mode = fiber.mode; // 1. 非ConcurrentMode模式 2. 目前不支持 if ((mode & ConcurrentMode) === NoMode) { return (SyncLane: Lane); } elseif ( (executionContext & RenderContext) !== NoContext && workInProgressRootRenderLanes !== NoLanes ) { // This is a render phase update. These are not officially supported. The // old behavior is to give this the same "thread" (lanes) as // whatever is currently rendering. So if you call `setState` on a component // that happens later in the same render, it will flush. Ideally, we want to // remove the special case and treat them as if they came from an // interleaved event. Regardless, this pattern is not officially supported. // This behavior is only a fallback. The flag only exists until we can roll // out the setState warning, since existing code might accidentally rely on // the current behavior. return pickArbitraryLane(workInProgressRootRenderLanes); }
// 普通更新与非紧急更新(18) const transition = requestCurrentTransition(); // 如果有transition if (transition !== null) { const actionScopeLane = peekEntangledActionLane(); return actionScopeLane !== NoLane ? // We're inside an async action scope. Reuse the same lane. actionScopeLane : // We may or may not be inside an async action scope. If we are, this // is the first update in that scope. Either way, we need to get a // fresh transition lane. requestTransitionLane(transition); }
// React内部的一些update,比如flushSync,会通过上下文变量来跟踪其优先级 const updateLane: Lane = (getCurrentUpdatePriority(): any); if (updateLane !== NoLane) { // ? sy setState click 2 return updateLane; }
exportfunctiongetEventPriority(domEventName: DOMEventName): EventPriority{ switch (domEventName) { // Used by SimpleEventPlugin: case'cancel': case'click': case'close': case'contextmenu': case'copy': case'cut': case'auxclick': case'dblclick': case'dragend': case'dragstart': case'drop': case'focusin': case'focusout': case'input': case'invalid': case'keydown': case'keypress': case'keyup': case'mousedown': case'mouseup': case'paste': case'pause': case'play': case'pointercancel': case'pointerdown': case'pointerup': case'ratechange': case'reset': case'resize': case'seeked': case'submit': case'touchcancel': case'touchend': case'touchstart': case'volumechange': // Used by polyfills: (fall through) case'change': case'selectionchange': case'textInput': case'compositionstart': case'compositionend': case'compositionupdate': // Only enableCreateEventHandleAPI: (fall through) case'beforeblur': case'afterblur': // Not used by React but could be by user code: (fall through) case'beforeinput': case'blur': case'fullscreenchange': case'focus': case'hashchange': case'popstate': case'select': case'selectstart': return DiscreteEventPriority; case'drag': case'dragenter': case'dragexit': case'dragleave': case'dragover': case'mousemove': case'mouseout': case'mouseover': case'pointermove': case'pointerout': case'pointerover': case'scroll': case'toggle': case'touchmove': case'wheel': // Not used by React but could be by user code: (fall through) case'mouseenter': case'mouseleave': case'pointerenter': case'pointerleave': return ContinuousEventPriority; case'message': { // We might be in the Scheduler callback. // Eventually this mechanism will be replaced by a check // of the current priority on the native scheduler. const schedulerPriority = getCurrentSchedulerPriorityLevel(); switch (schedulerPriority) { case ImmediateSchedulerPriority: return DiscreteEventPriority; case UserBlockingSchedulerPriority: return ContinuousEventPriority; case NormalSchedulerPriority: case LowSchedulerPriority: // TODO: Handle LowSchedulerPriority, somehow. Maybe the same lane as hydration. return DefaultEventPriority; case IdleSchedulerPriority: return IdleEventPriority; default: return DefaultEventPriority; } } default: return DefaultEventPriority; } }
let newBaseState = null; let newBaseQueueFirst = null; let newBaseQueueLast: Update<S, A> | null = null; // 跳过的这些更新(低优先级任务)会被保存在这个循环链表中 let update = first; let didReadFromEntangledAsyncAction = false; do { // An extra OffscreenLane bit is added to updates that were made to // a hidden tree, so that we can distinguish them from updates that were // already there when the tree was hidden. const updateLane = removeLanes(update.lane, OffscreenLane); const isHiddenUpdate = updateLane !== update.lane;
// Check if this update was made while the tree was hidden. If so, then // it's not a "base" update and we should disregard the extra base lanes // that were added to renderLanes when we entered the Offscreen tree. const shouldSkipUpdate = isHiddenUpdate ? !isSubsetOfLanes(getWorkInProgressRootRenderLanes(), updateLane) : !isSubsetOfLanes(renderLanes, updateLane);
// 当前任务的优先级不够,也就是说当前的 renderLanes 比该 update 对象的优先级高。需要先跳过,之后再处理。 if (shouldSkipUpdate) { // Priority is insufficient. Skip this update. If this is the first // skipped update, the previous update/state is the new base // update/state. const clone: Update<S, A> = { lane: updateLane, revertLane: update.revertLane, action: update.action, hasEagerState: update.hasEagerState, eagerState: update.eagerState, next: (null: any), }; // 如果在当前被跳过的 update 对象之前没有其他的 update 被跳过,该对象就是作为新的基础更新对象。并把最初跳过任务时候的 baseState 存储起来 if (newBaseQueueLast === null) { newBaseQueueFirst = newBaseQueueLast = clone; newBaseState = newState; } else { // 如果之前有更新被跳过,那么将这个更新对象添加到队列最后 newBaseQueueLast = newBaseQueueLast.next = clone; } // 更新当前正在工作的 Fiber 节点(workInProgress)的优先级,标记这个更新对象的优先级由于不匹配当前的 renderLane,因此已经被跳过。 // 在同文件的 renderWithHook() 方法中可以知道 currentlyRenderingFiber 对应了 workInProgress,表示当前正在工作的 fiber 树 currentlyRenderingFiber.lanes = mergeLanes( currentlyRenderingFiber.lanes, updateLane, ); markSkippedUpdateLanes(updateLane); } else { // 优先级足够 // 优先级足够的时候理论上可以考虑对哪些 update 对象进行收集更新,但是此时还需要考虑一个 revertLane(还原的优先级),以保证组件状态的正确。 // This update does have sufficient priority.
// Check if this is an optimistic update. const revertLane = update.revertLane; if (!enableAsyncActions || revertLane === NoLane) { // ? sy // This is not an optimistic update, and we're going to apply it now. // But, if there were earlier updates that were skipped, we need to // leave this update in the queue so it can be rebased later. // 如果 newBaseQueueLast 不为 null,证明有跳过的更新,要把当前的update也加入newBaseQueueLast只是到其 lane 会赋值为 0,后面进行低优先级的更新时,这些已经被处理过的更新也仍旧会被处理,保证最后计算的数据是正确的 if (newBaseQueueLast !== null) { const clone: Update<S, A> = { // This update is going to be committed so we never want uncommit // it. Using NoLane works because 0 is a subset of all bitmasks, so // this will never be skipped by the check above. lane: NoLane, revertLane: NoLane, action: update.action, hasEagerState: update.hasEagerState, eagerState: update.eagerState, next: (null: any), }; newBaseQueueLast = newBaseQueueLast.next = clone; }
// Check if this update is part of a pending async action. If so, // we'll need to suspend until the action has finished, so that it's // batched together with future updates in the same action. if (updateLane === peekEntangledActionLane()) { // ? sy-no didReadFromEntangledAsyncAction = true; } } else { // This is an optimistic update. If the "revert" priority is // sufficient, don't apply the update. Otherwise, apply the update, // but leave it in the queue so it can be either reverted or // rebased in a subsequent render. if (isSubsetOfLanes(renderLanes, revertLane)) { // The transition that this optimistic update is associated with // has finished. Pretend the update doesn't exist by skipping // over it. update = update.next;
// Check if this update is part of a pending async action. If so, // we'll need to suspend until the action has finished, so that it's // batched together with future updates in the same action. if (revertLane === peekEntangledActionLane()) { didReadFromEntangledAsyncAction = true; } continue; } else { const clone: Update<S, A> = { // Once we commit an optimistic update, we shouldn't uncommit it // until the transition it is associated with has finished // (represented by revertLane). Using NoLane here works because 0 // is a subset of all bitmasks, so this will never be skipped by // the check above. lane: NoLane, // Reuse the same revertLane so we know when the transition // has finished. revertLane: update.revertLane, action: update.action, hasEagerState: update.hasEagerState, eagerState: update.eagerState, next: (null: any), }; if (newBaseQueueLast === null) { newBaseQueueFirst = newBaseQueueLast = clone; newBaseState = newState; } else { newBaseQueueLast = newBaseQueueLast.next = clone; } // Update the remaining priority in the queue. // TODO: Don't need to accumulate this. Instead, we can remove // renderLanes from the original lanes. currentlyRenderingFiber.lanes = mergeLanes( currentlyRenderingFiber.lanes, revertLane, ); markSkippedUpdateLanes(revertLane); } }
// 该 update 对象的优先级足够,因此开始处理它的 action,收集新的 state 状态 const action = update.action; if (shouldDoubleInvokeUserFnsInHooksDEV) { reducer(newState, action); } if (update.hasEagerState) { // If this update is a state update (not a reducer) and was processed eagerly, // we can use the eagerly computed state newState = ((update.eagerState: any): S); } else { // ! 计算useReducer的新的state newState = reducer(newState, action); } } // 循环 baseQueue(实际上就是 pendingQueue),处理该队列中的每个 update 对象, // 并把对应的 action 操作得到的结果更新到 newState 中(即收集新状态) update = update.next; } while (update !== null && update !== first);
// Mark that the fiber performed work, but only if the new state is // different from the current state. if (!is(newState, hook.memoizedState)) { markWorkInProgressReceivedUpdate();
if (baseQueue === null) { // `queue.lanes` is used for entangling transitions. We can set it back to // zero once the queue is empty. queue.lanes = NoLanes; }
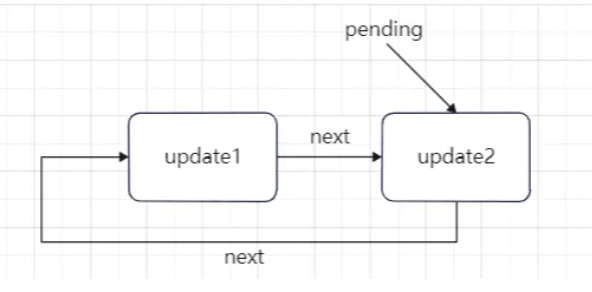
functionenqueueRenderPhaseUpdate<S, A>( queue: UpdateQueue<S, A>, update: Update<S, A>, ): void{ // This is a render phase update. Stash it in a lazily-created map of // queue -> linked list of updates. After this render pass, we'll restart // and apply the stashed updates on top of the work-in-progress hook. didScheduleRenderPhaseUpdateDuringThisPass = didScheduleRenderPhaseUpdate = true; const pending = queue.pending; if (pending === null) { // This is the first update. Create a circular list. update.next = update; } else { update.next = pending.next; pending.next = update; } queue.pending = update; }
// Check if there was a render phase update // enqueueRenderPhaseUpdate会给didScheduleRenderPhaseUpdateDuringThisPass设置为true,所以下面还会render一次,这也就是setState嵌套setState的情况下render连续 2次 if (didScheduleRenderPhaseUpdateDuringThisPass) { // Keep rendering until the component stabilizes (there are no more render // phase updates). children = renderWithHooksAgain( workInProgress, Component, props, secondArg, ); }
这个优化策略的作用是:调用 queue.lastRenderedReducer 方法,通过原来的 state 和当前传入的 action 参数,快速的计算出本次最新的 state 【即eagerState】,通过比较新旧 state 来判断数据是否变化,如果没有变化则可以跳过后续的更新逻辑,即不会开启新的调度更新任务。当前我们的 state 是有变化的,所以不满足优化策略,将继续向下执行更新。
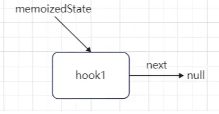
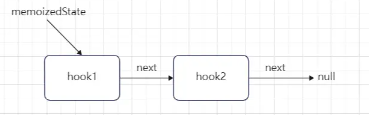
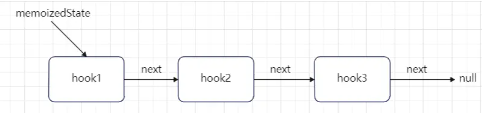
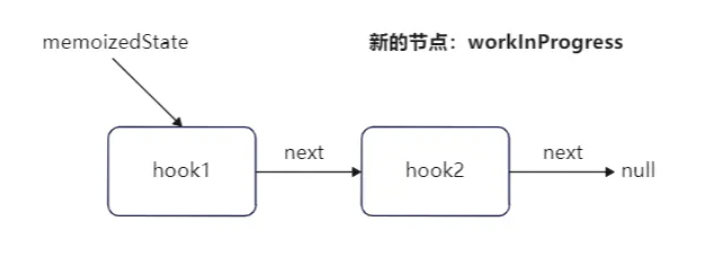
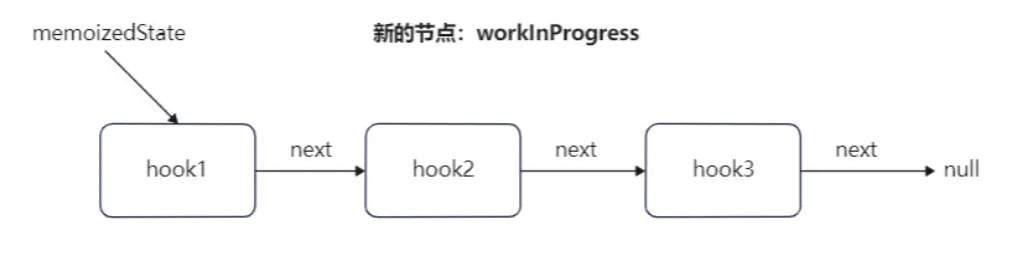
// 第一个hook更新时,workInProgressHook为null,会进入这里 if (workInProgressHook === null) { // This is the first hook in the list. // 更新当前函数的组件的memoizedState为第一个hook对象,同时设置为当前正在工作中的hook currentlyRenderingFiber.memoizedState = workInProgressHook = newHook; } else { // Append to the end of the list. // 非第一个Hook,直接添加到上一个hook对象的next属性中 workInProgressHook = workInProgressHook.next = newHook; } } // 返回当前正在工作中的hook return workInProgressHook; }
functionupdateReducer<S, I, A>( reducer: (S, A) => S, initialArg: I, init?: I => S, ): [S, Dispatch<A>] { // 返回新的hook对象 const hook = updateWorkInProgressHook(); const queue = hook.queue;
if (queue === null) { thrownewError( 'Should have a queue. This is likely a bug in React. Please file an issue.', ); }
queue.lastRenderedReducer = reducer; // 还是basicStateReducer,无变化 const current = currentHook; // 旧的hook对象,加载时useState创建的hook对象 // The last rebase update that is NOT part of the base state. let baseQueue = current.baseQueue;
// The last pending update that hasn't been processed yet. // 等待处理的更新链表:默认指向的是最后一个update对象 const pendingQueue = queue.pending; if (pendingQueue !== null) { // pendingQueue不为null,代表有需要处理的更新对象,然后需要将它们添加到baseQueue if (baseQueue !== null) { // Merge the pending queue and the base queue. const baseFirst = baseQueue.next; const pendingFirst = pendingQueue.next; baseQueue.next = pendingFirst; pendingQueue.next = baseFirst; } current.baseQueue = baseQueue = pendingQueue; queue.pending = null; }
if (baseQueue !== null) { // 我们有一个队列要处理 const first = baseQueue.next; let newState = current.baseState;
let newBaseState = null; let newBaseQueueFirst = null; let newBaseQueueLast = null; let update = first;
# 循环处理update更新对象 do { // An extra OffscreenLane bit is added to updates that were made to // a hidden tree, so that we can distinguish them from updates that were // already there when the tree was hidden. const updateLane = removeLanes(update.lane, OffscreenLane); const isHiddenUpdate = updateLane !== update.lane;
// Check if this update was made while the tree was hidden. If so, then // it's not a "base" update and we should disregard the extra base lanes // that were added to renderLanes when we entered the Offscreen tree. const shouldSkipUpdate = isHiddenUpdate ? !isSubsetOfLanes(getWorkInProgressRootRenderLanes(), updateLane) : !isSubsetOfLanes(renderLanes, updateLane);
if (shouldSkipUpdate) { // Priority is insufficient. Skip this update. If this is the first // skipped update, the previous update/state is the new base // update/state. const clone: Update<S, A> = { lane: updateLane, action: update.action, hasEagerState: update.hasEagerState, eagerState: update.eagerState, next: (null: any), }; if (newBaseQueueLast === null) { newBaseQueueFirst = newBaseQueueLast = clone; newBaseState = newState; } else { newBaseQueueLast = newBaseQueueLast.next = clone; } // Update the remaining priority in the queue. // TODO: Don't need to accumulate this. Instead, we can remove // renderLanes from the original lanes. currentlyRenderingFiber.lanes = mergeLanes( currentlyRenderingFiber.lanes, updateLane, ); markSkippedUpdateLanes(updateLane); } else { // This update does have sufficient priority.
if (newBaseQueueLast !== null) { const clone: Update<S, A> = { // This update is going to be committed so we never want uncommit // it. Using NoLane works because 0 is a subset of all bitmasks, so // this will never be skipped by the check above. lane: NoLane, action: update.action, hasEagerState: update.hasEagerState, eagerState: update.eagerState, next: (null: any), }; newBaseQueueLast = newBaseQueueLast.next = clone;
// Process this update. if (update.hasEagerState) { // If this update is a state update (not a reducer) and was processed eagerly, // we can use the eagerly computed state newState = ((update.eagerState: any): S); } else { const action = update.action; newState = reducer(newState, action); } } update = update.next; } while (update !== null && update !== first);