mount( rootContainer: HostElement, isHydrate?: boolean, namespace?: boolean | ElementNamespace, ) { if (!isMounted) { // #5571 if (__DEV__ && (rootContainer as any).__vue_app__) { warn( `There is already an app instance mounted on the host container.\n` + ` If you want to mount another app on the same host container,` + ` you need to unmount the previous app by calling \`app.unmount()\` first.`, ) } const vnode = createVNode(rootComponent, rootProps) // store app context on the root VNode. // this will be set on the root instance on initial mount. vnode.appContext = context
// HMR root reload if (__DEV__) { context.reload = () => { // casting to ElementNamespace because TS doesn't guarantee type narrowing // over function boundaries render( cloneVNode(vnode), rootContainer, namespace as ElementNamespace, ) } }
if (isHydrate && hydrate) { hydrate(vnode as VNode<Node, Element>, rootContainer as any) } else { render(vnode, rootContainer, namespace) } isMounted = true app._container = rootContainer // for devtools and telemetry ;(rootContainer as any).__vue_app__ = app
return getExposeProxy(vnode.component!) || vnode.component!.proxy } elseif (__DEV__) { warn( `App has already been mounted.\n` + `If you want to remount the same app, move your app creation logic ` + `into a factory function and create fresh app instances for each ` + `mount - e.g. \`const createMyApp = () => createApp(App)\``, ) } }
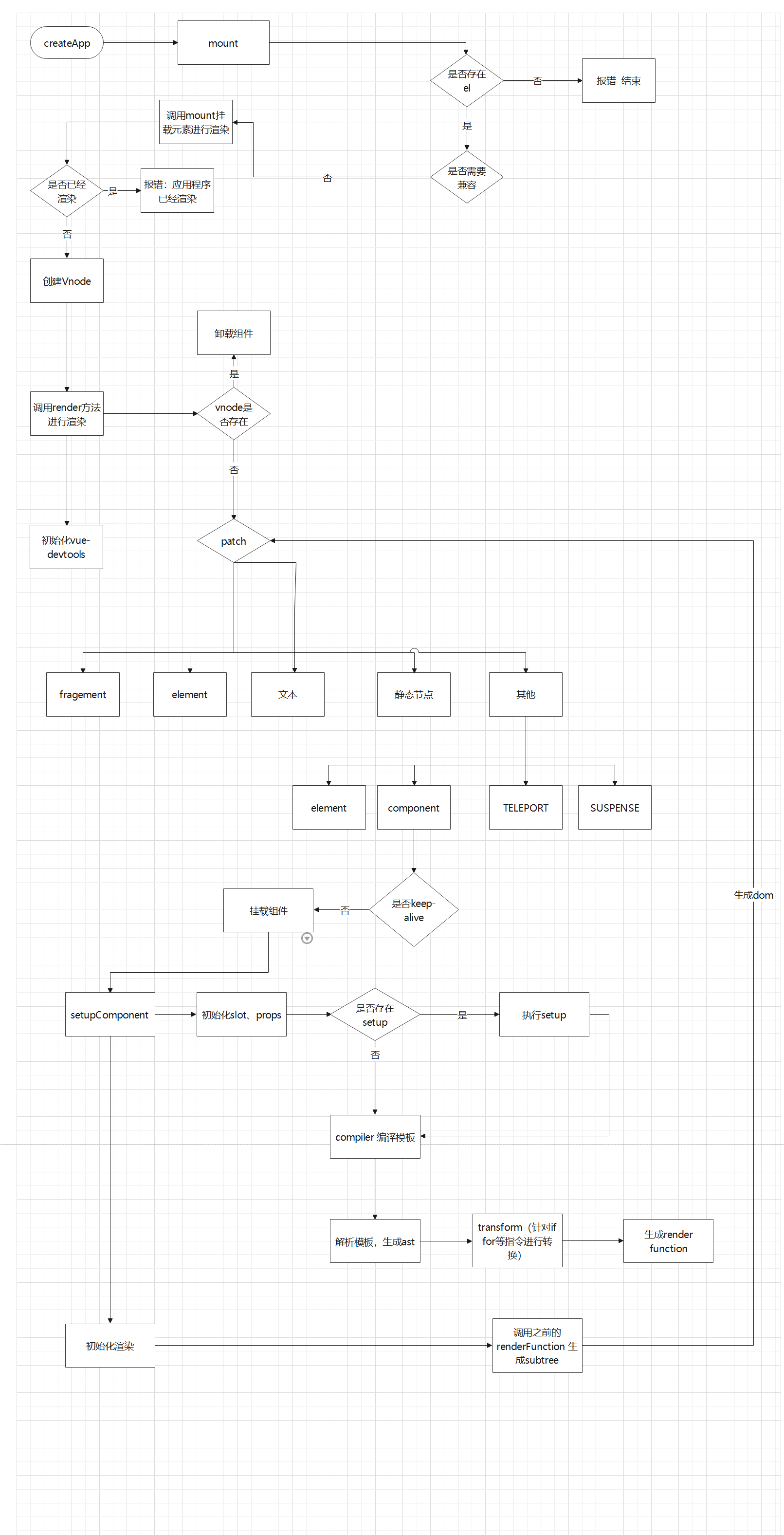
// resolve props and slots for setup context if (!(__COMPAT__ && compatMountInstance)) { if (__DEV__) { startMeasure(instance, `init`) } // 2.设置组件实例 // 初始化组件, 主要是对组件的props/slots进行初始化处理 // 执行setup 生成render函数(所以setup是在所有选项式API钩子之前调用 包括beforeCreate) setupComponent(instance) if (__DEV__) { endMeasure(instance, `init`) } }
// setup() is async. This component relies on async logic to be resolved // before proceeding if (__FEATURE_SUSPENSE__ && instance.asyncDep) { // ... } else { // 3.调用设置和运行有副作用的渲染函数
if (isPromise(setupResult)) { setupResult.then(unsetCurrentInstance, unsetCurrentInstance) if (isSSR) { // return the promise so server-renderer can wait on it return setupResult .then((resolvedResult: unknown) => { handleSetupResult(instance, resolvedResult, isSSR) }) .catch(e => { handleError(e, instance, ErrorCodes.SETUP_FUNCTION) }) } elseif (__FEATURE_SUSPENSE__) { // async setup returned Promise. // bail here and wait for re-entry. instance.asyncDep = setupResult if (__DEV__ && !instance.suspense) { const name = Component.name ?? 'Anonymous' warn( `Component <${name}>: setup function returned a promise, but no ` + `<Suspense> boundary was found in the parent component tree. ` + `A component with async setup() must be nested in a <Suspense> ` + `in order to be rendered.`, ) } } elseif (__DEV__) { warn( `setup() returned a Promise, but the version of Vue you are using ` + `does not support it yet.`, ) } } else { handleSetupResult(instance, setupResult, isSSR) } } else { finishComponentSetup(instance, isSSR) } }
// patch新旧节点更新组件 patch( prevTree, nextTree, // parent may have changed if it's in a teleport hostParentNode(prevTree.el!)!, // anchor may have changed if it's in a fragment getNextHostNode(prevTree), instance, parentSuspense, isSVG ) // ... } }
pauseTracking() // props update may have triggered pre-flush watchers. // flush them before the render update. flushPreFlushCbs(instance) resetTracking() }
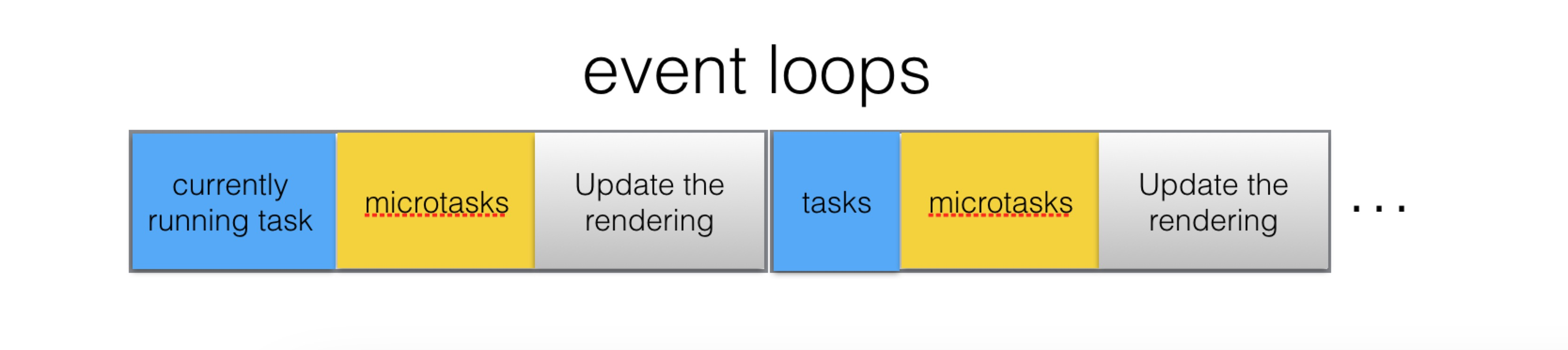
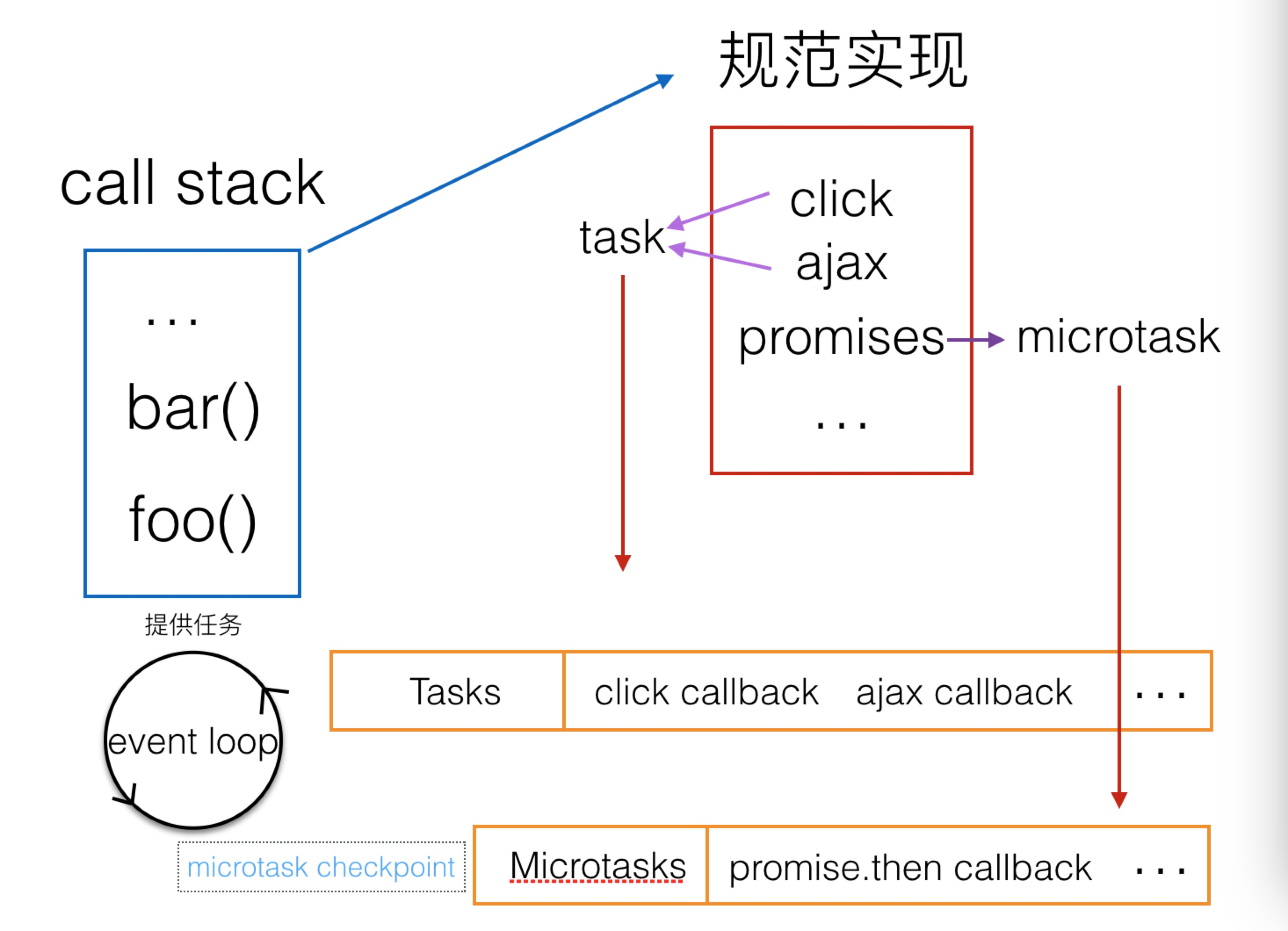
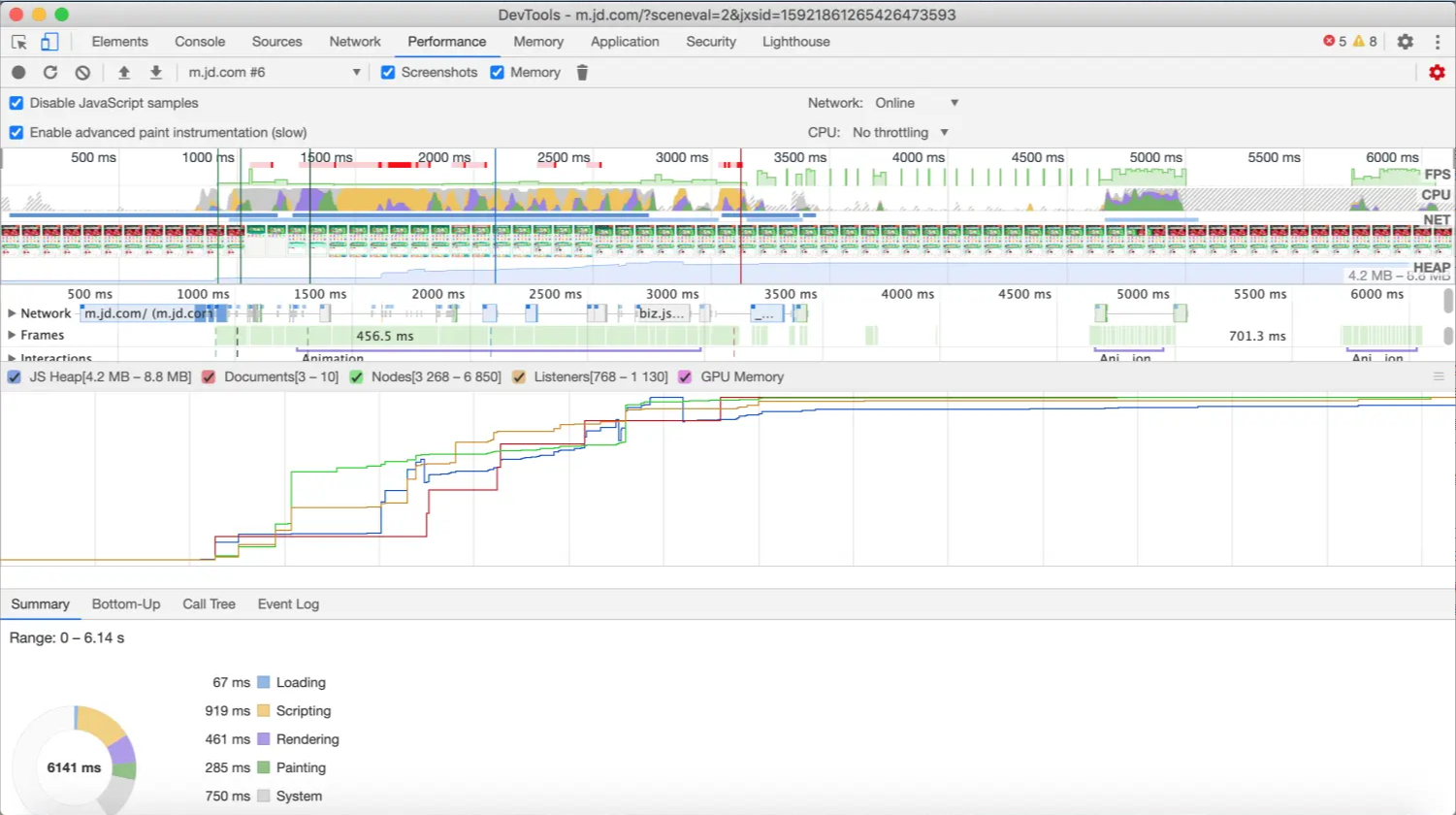
下面讨论一下渲染的时机。规范定义在一次循环中,Update the rendering 会在 Microtasks: Perform a microtask checkpoint 后运行。
渲染时机
以下的例子中,用 chrome 的 Developer tools 的 Timeline 查看各部分运行的时间点。当我们点击这个 div 的时候,截取了部分时间线。
黄色部分是脚本运行,紫色部分是更新 render 树、计算布局,绿色部分是绘制。
绿色和紫色部分可以认为是 Update the rendering。
例子 1
1 2 3 4 5 6 7 8 9 10
<divid="con">this is con</div> <script> var t = 0 var con = document.getElementById('con') con.onclick = function(){ setTimeout(functionsetTimeout1(){ con.textContent = t }, 0) } </script>
<divid="con">this is con</div> <script> var con = document.getElementById('con') var i = 0 var raf = function(){ requestAnimationFrame(function(){ con.textContent = i Promise.resolve().then(function () { i++ if (i < 3) raf() }) }) } con.onclick = function(){ raf() } </script>
map of animation frame callbacks 为空,也就是帧动画回调为空,可以通过 requestAnimationFrame 来请求帧动画。
如果上述的判断决定本轮不需要渲染,那么下面的几步也不会继续运行:
This step enables the user agent to prevent the steps below from running for other reasons, for example, to ensure certain tasks are executed immediately after each other, with only microtask checkpoints interleaved (and without, e.g., animation frame callbacks interleaved). Concretely, a user agent might wish to coalesce timer callbacks together, with no intermediate rendering updates. 有时候浏览器希望两次「定时器任务」是合并的,他们之间只会穿插着 microTask 的执行,而不会穿插屏幕渲染相关的流程
An event loop has one or more task queues. For example, a user agent could have one task queue for mouse and key events (to which the user interaction task source is associated), and another to which all other task sources are associated. Then, using the freedom granted in the initial step of the event loop processing model, it could give keyboard and mouse events preference over other tasks three-quarters of the time, keeping the interface responsive but not starving other task queues. Note that in this setup, the processing model still enforces that the user agent would never process events from any one task source out of order.
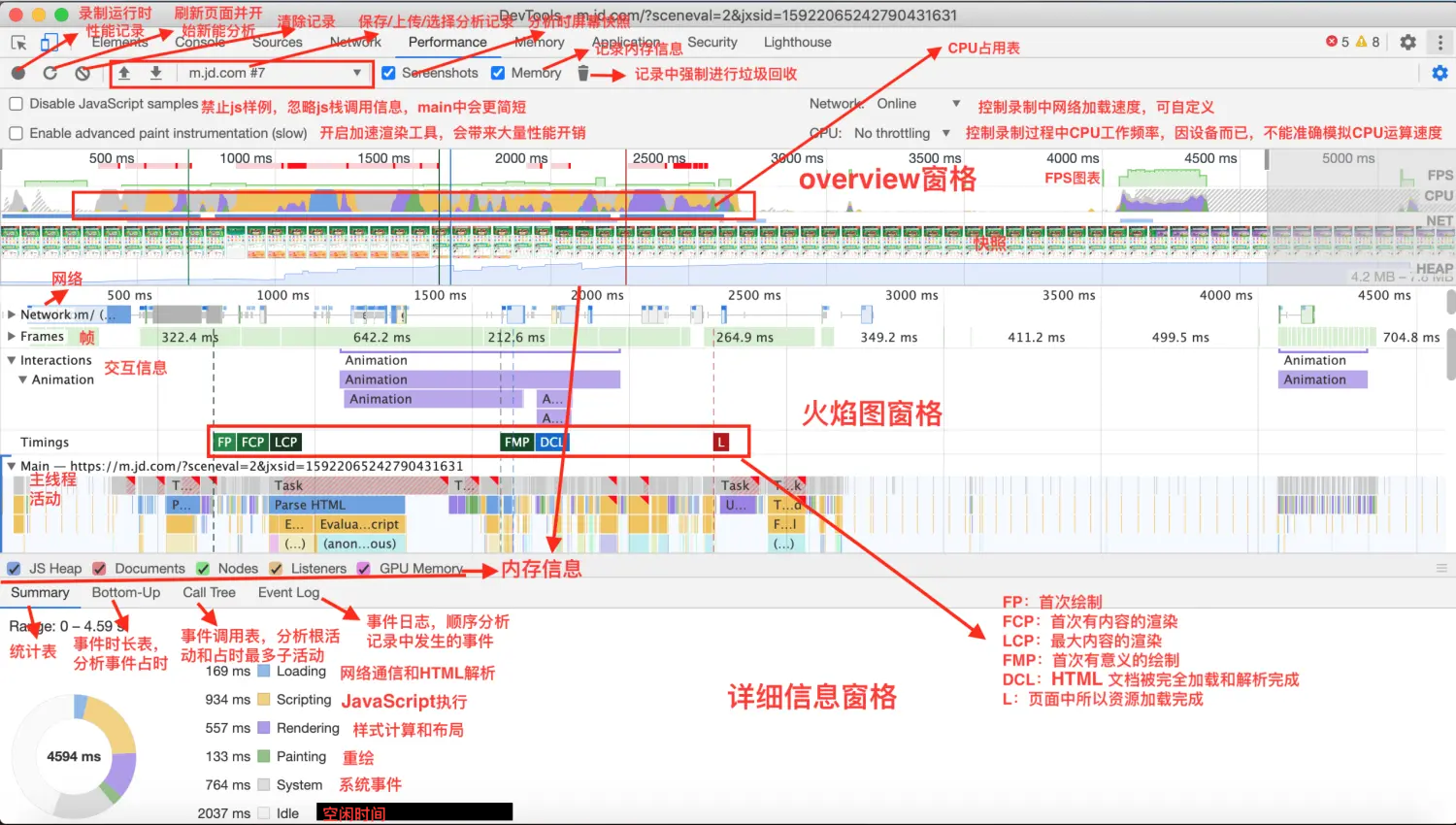
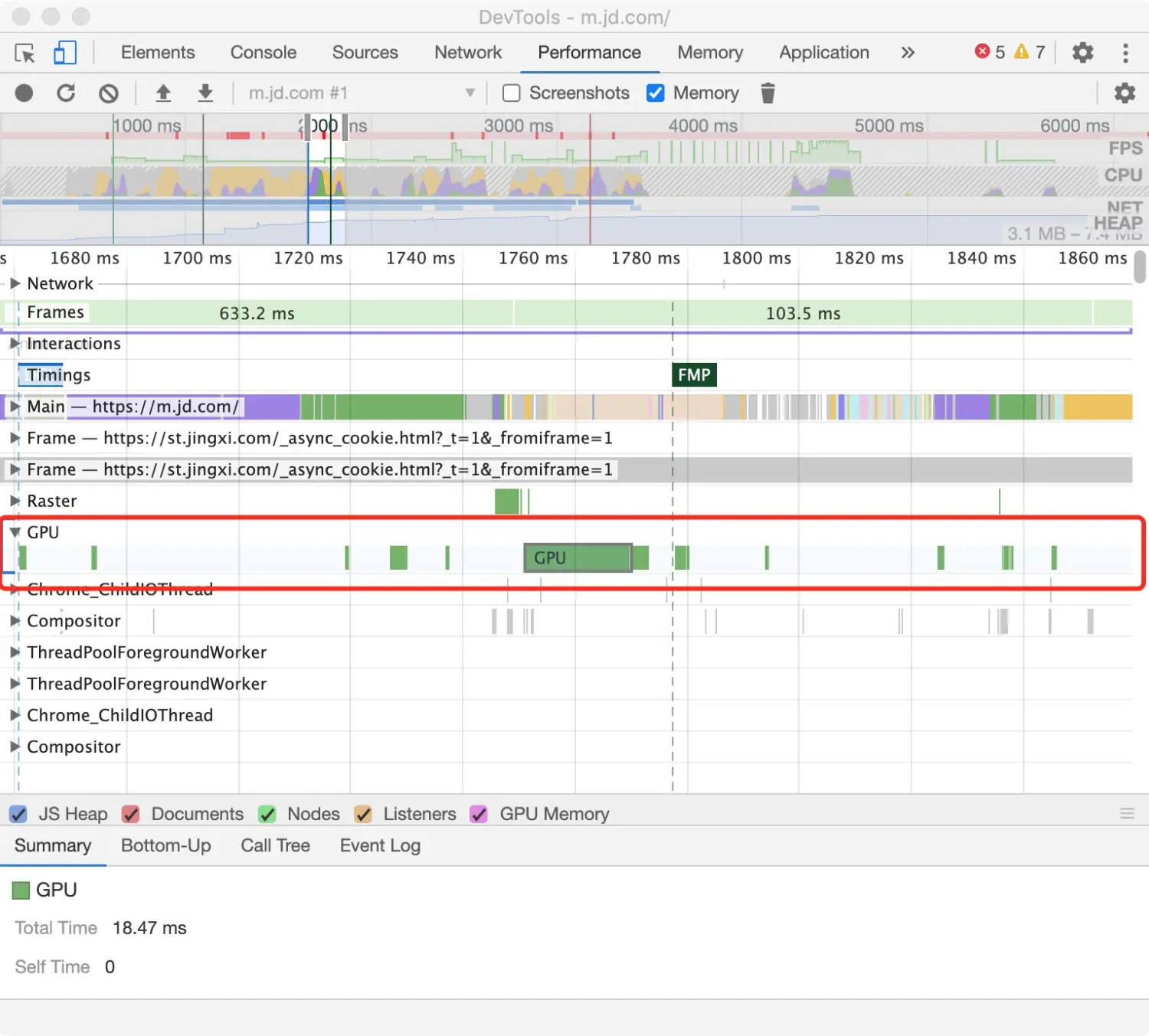
根活动指的是浏览器触发的一系列流程。例如,当你点击页面内容,浏览器触发一个 Event 作为根活动,该 Event 可能回调一个事件处理事件。 在 Main 面板中的火焰图中,根活动展示在上部,在 Call Tree 和 Event Log 面板中,根活动展示在顶层。
Call Tree 标签页
Call Tree 标签页中展示记录中被选中部分的活动信息。
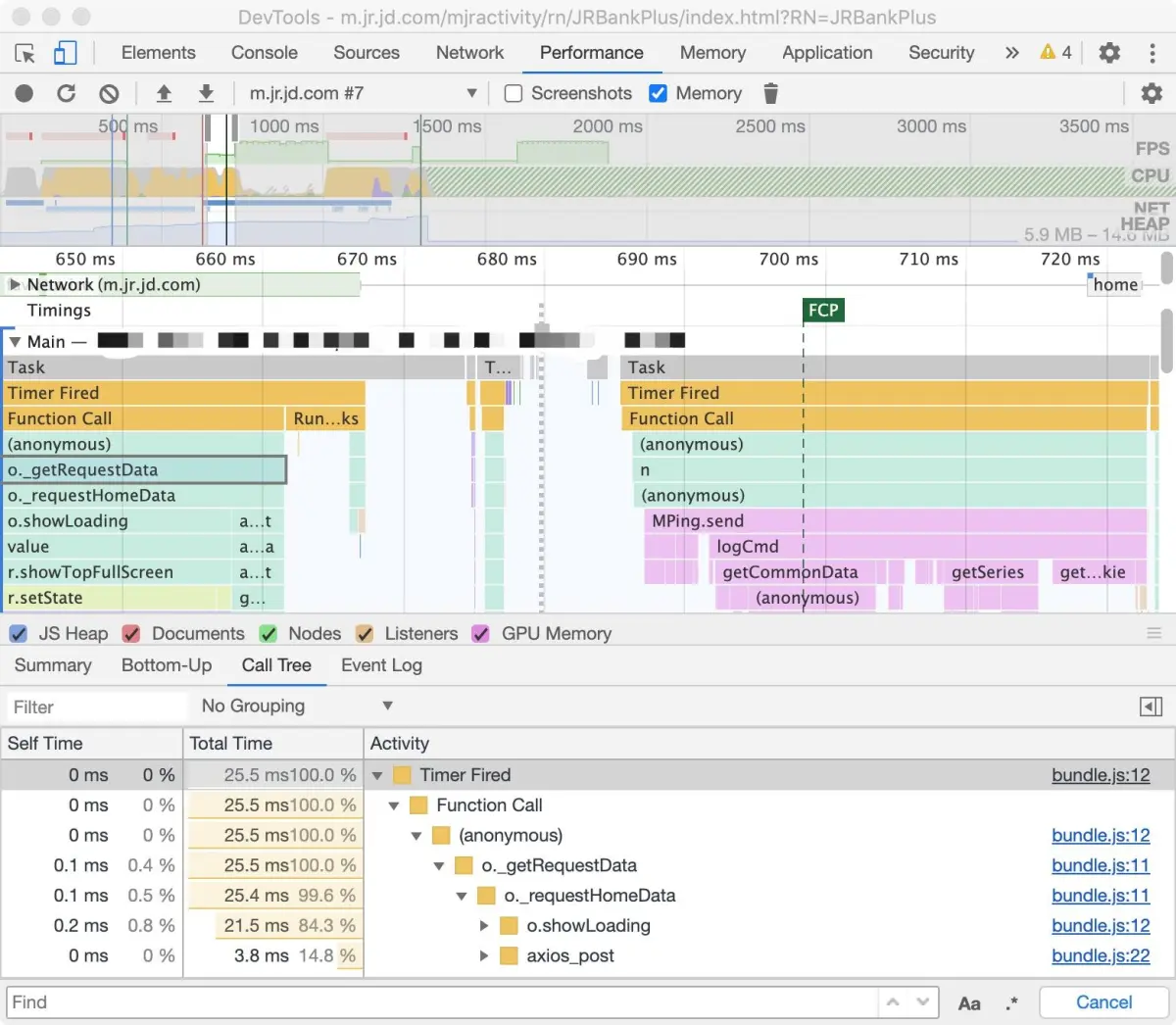
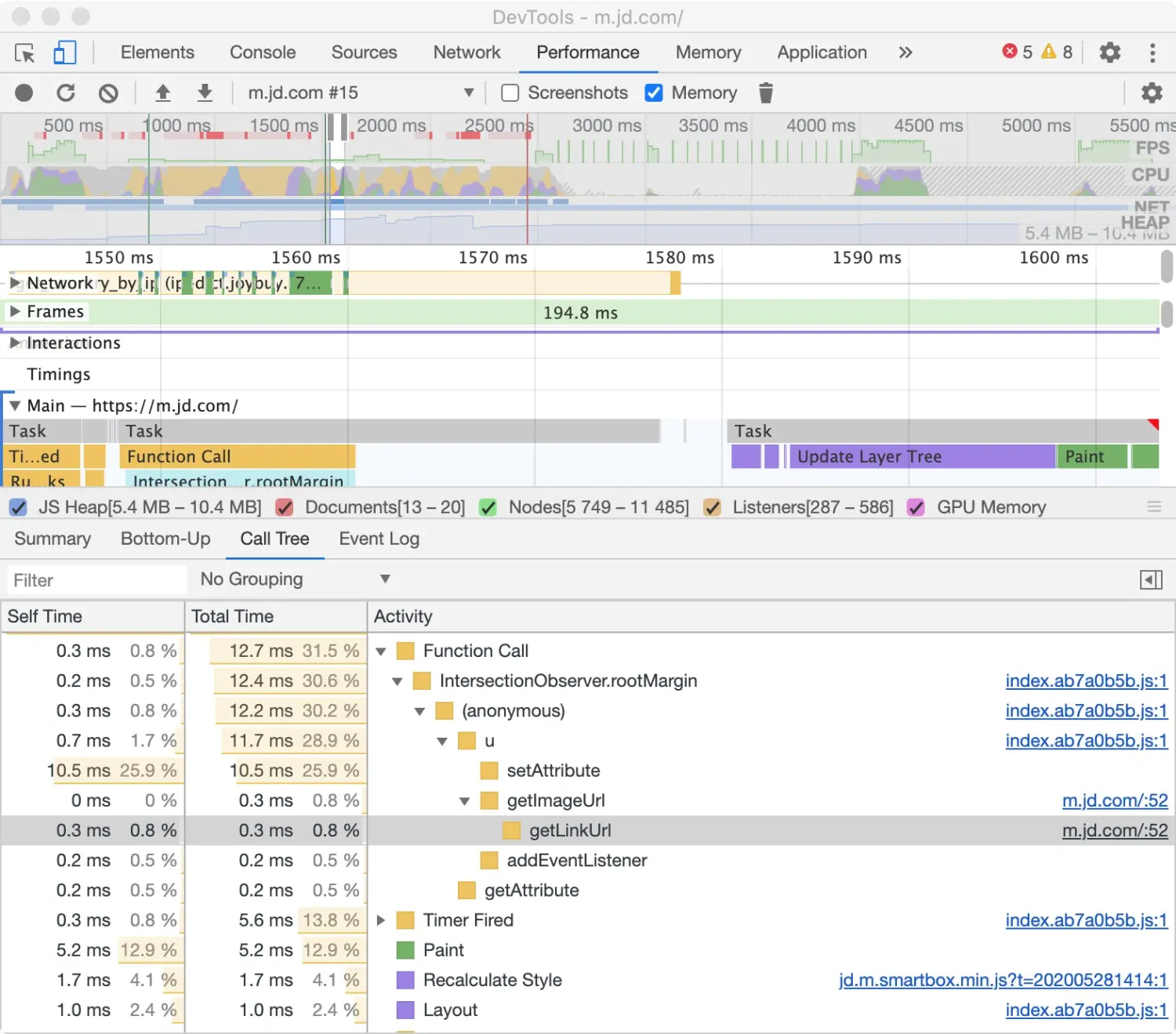
图中 Activity 列中显示的 Timer fired、 Paint、Recalculate Style 和 Layout 代表根活动。层级嵌套表示代表回调栈。如图中 Function Call 调用 u,再调用 getImageUrl,继续调用 getLinkUrl 等等。 Self Time 表示对应活动消耗的时间,Total Time 表示对应活动以及子活动共同消耗的时间。 点击 Self Time,Total Time 或者 Activity 表头区域,可按对应列排序。 利用 Filter 输入框区域,输入活动名过滤事件。 Grouping 分组菜单默认为 No Grouping,利用该功能可以根据不同的分类将活动进行分组。 点击右侧 Show Heaviest Stack,在右侧展示当前选中活动中占用时间最多的子活动信息。
Bottom-Up 标签页
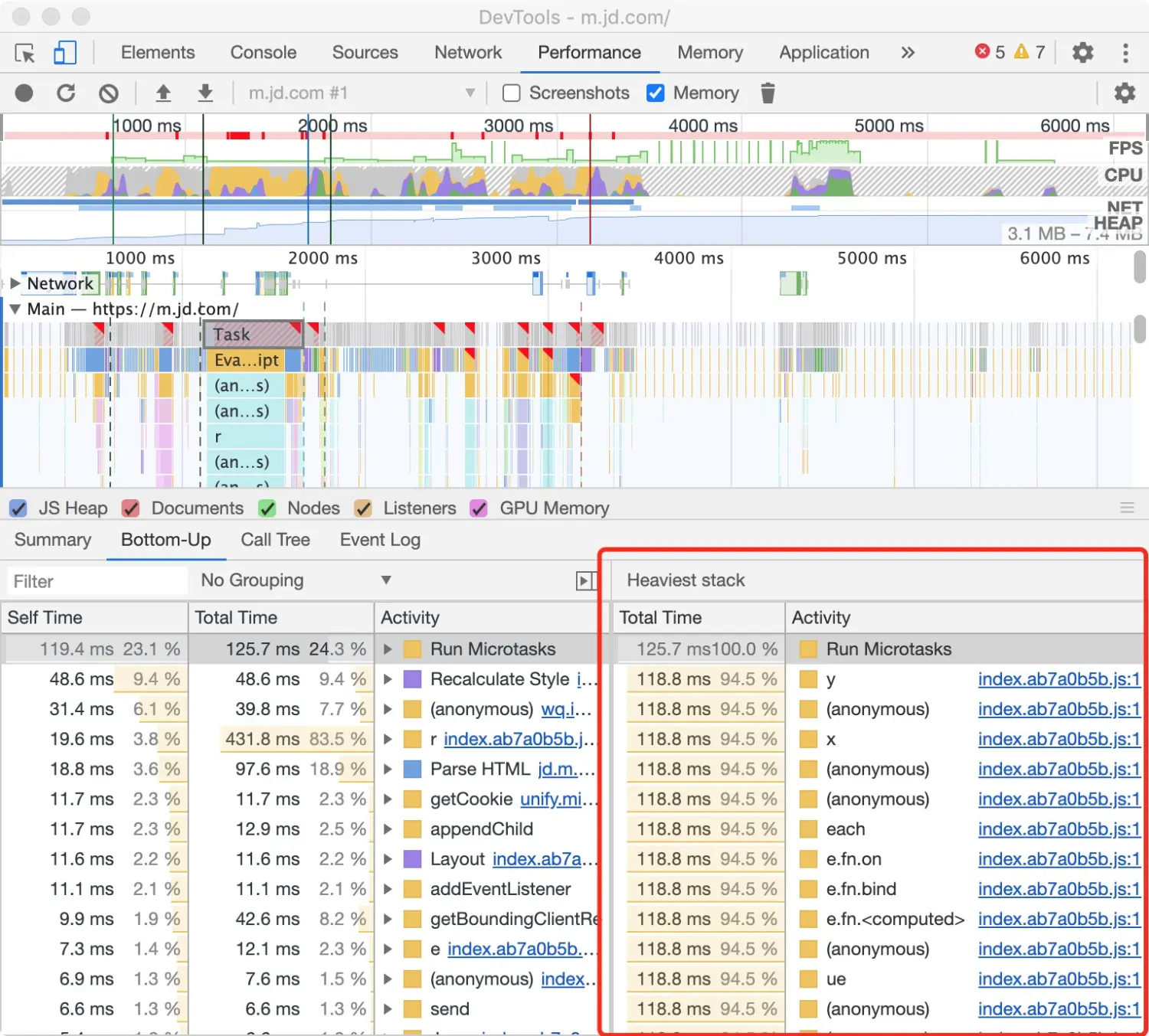
利用 Bottom-Up 标签查看占用最多时间的活动。 Self Time 表示对应活动消耗的时间。 Total Time 表示对应活动以及子活动共同消耗的时间。
Event Log 标签页
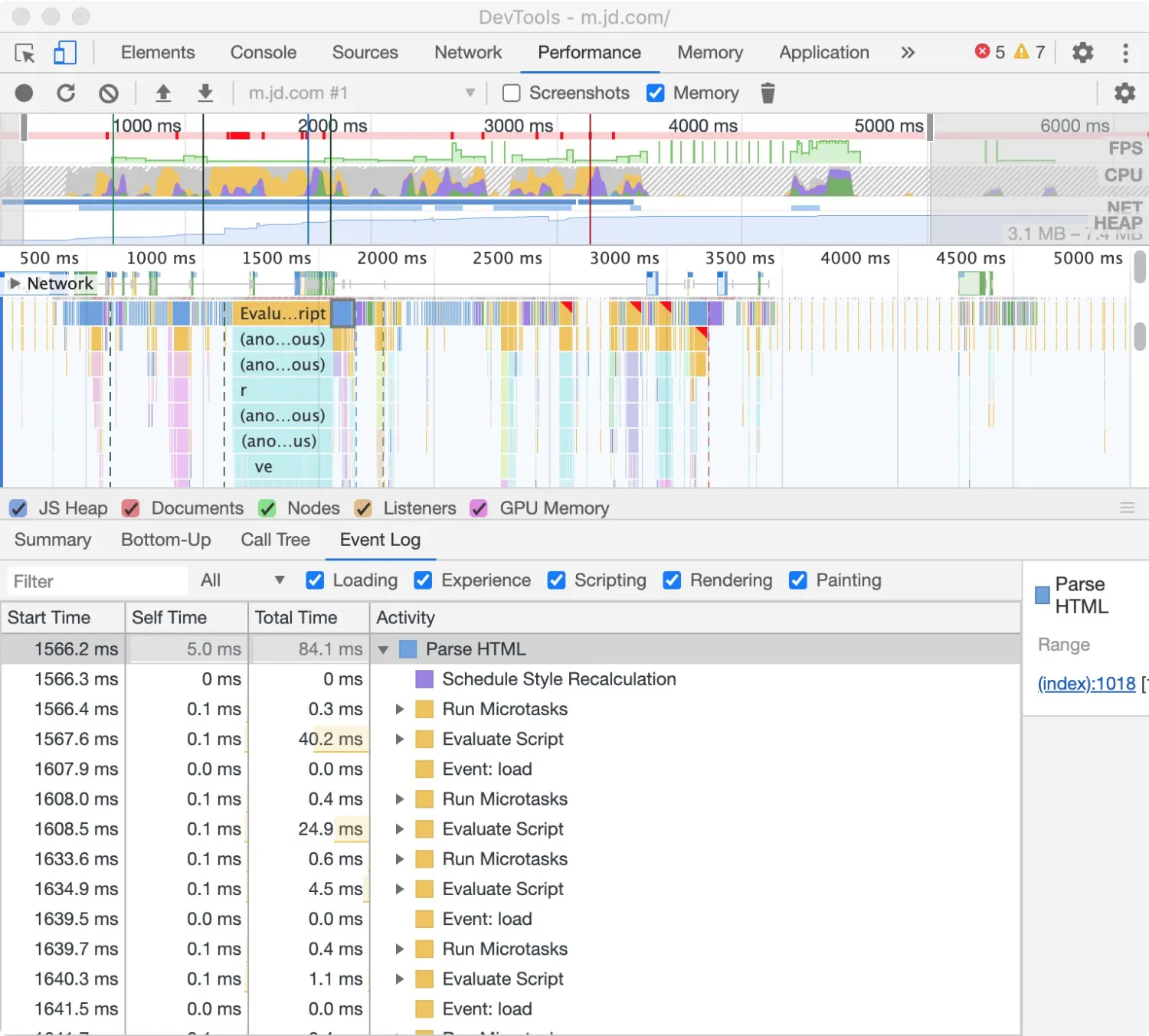
Event Log 标签页按顺序展示记录中发生的活动。 Start Time 列表示该项活动的开始时间,该时间相对于记录开始时间计算。例如图中选中项开始时间为 1566.2 ms,代表该活动在记录开始之后 1566.2 ms 后开始。 Self Time 表示对应活动消耗的时间。 Total Time 表示对应活动以及子活动共同消耗的时间。 点击 Start Time 、Self Time、Total Time 表头区域,可按对应列排序。 利用 Filter 输入框区域,输入活动名过滤事件。 利用 Duration 下拉菜单过滤>=1ms 或者>=15ms 的活动。该菜单默认选中 All 选项,展示所有活动。 利用 Loading、Experience、Scripting、Rendering、Painting 选项进行分类过滤。
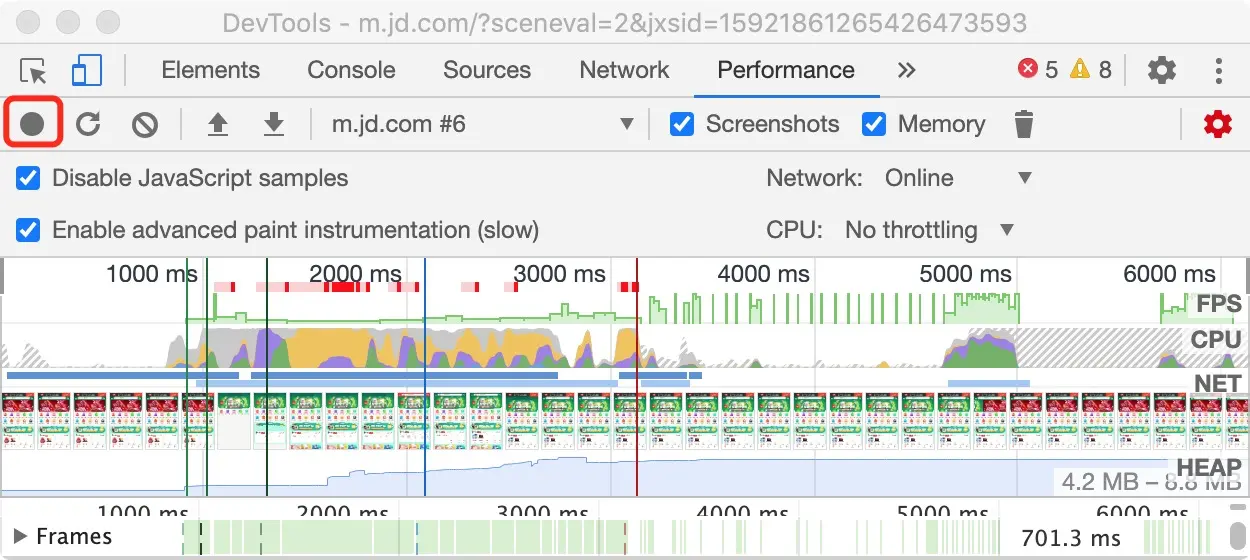
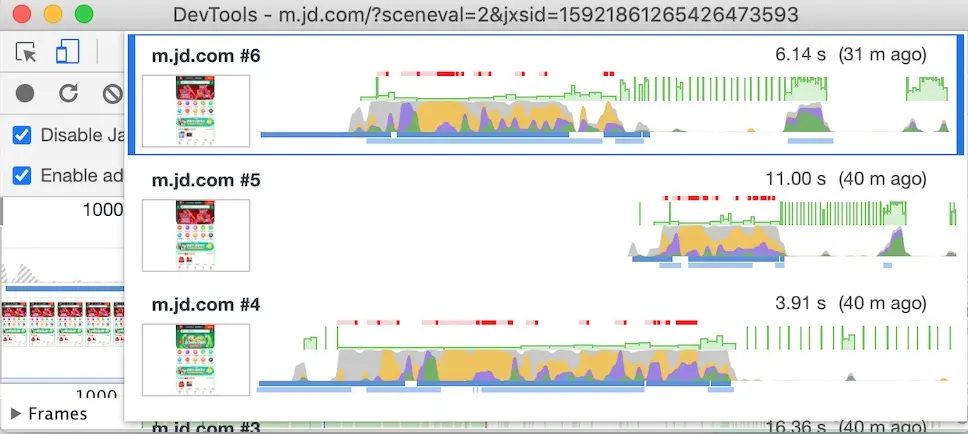
分析每秒传输帧数(FPS)
查看 FPS 图表了解整个记录中 FPS 的概况。
Frames 模块查看每一帧时间消耗。
利用 FPS meter 工具(MoreTools—>Rendering)在页面运行时实时查看 FPS 信息。
checkForLatestVersion(`${host}create-my-app/latest`) .catch(() => { try { return execSync('npm view create-my-app version').toString().trim() } catch (e) { returnnull } }) .then((latest) => { if (latest && semver.lt(packageJson.version, latest)) { console.log() console.error( chalk.yellow( `You are running \`create-my-app\` ${packageJson.version}, which is behind the latest release (${latest}).\n\n` + 'We recommend always using the latest version of create-my-app if possible.' ) ) console.log() console.log( 'The latest instructions for creating a new app can be found here:\n' + `${host}-/web/detail/create-my-app` ) console.log() } else { createApp() } })